
Che cos'è Robots.txt?
Robots.txt è un file di testo che contiene istruzioni per i robot dei motori di ricerca su quali pagine possono o non possono scansionare.
Queste istruzioni consistono nel "consentire" (allow) o "non consentire" (disallow) il passaggio di alcuni (o di tutti) i bot.
Ecco come si presenta un file robots.txt:
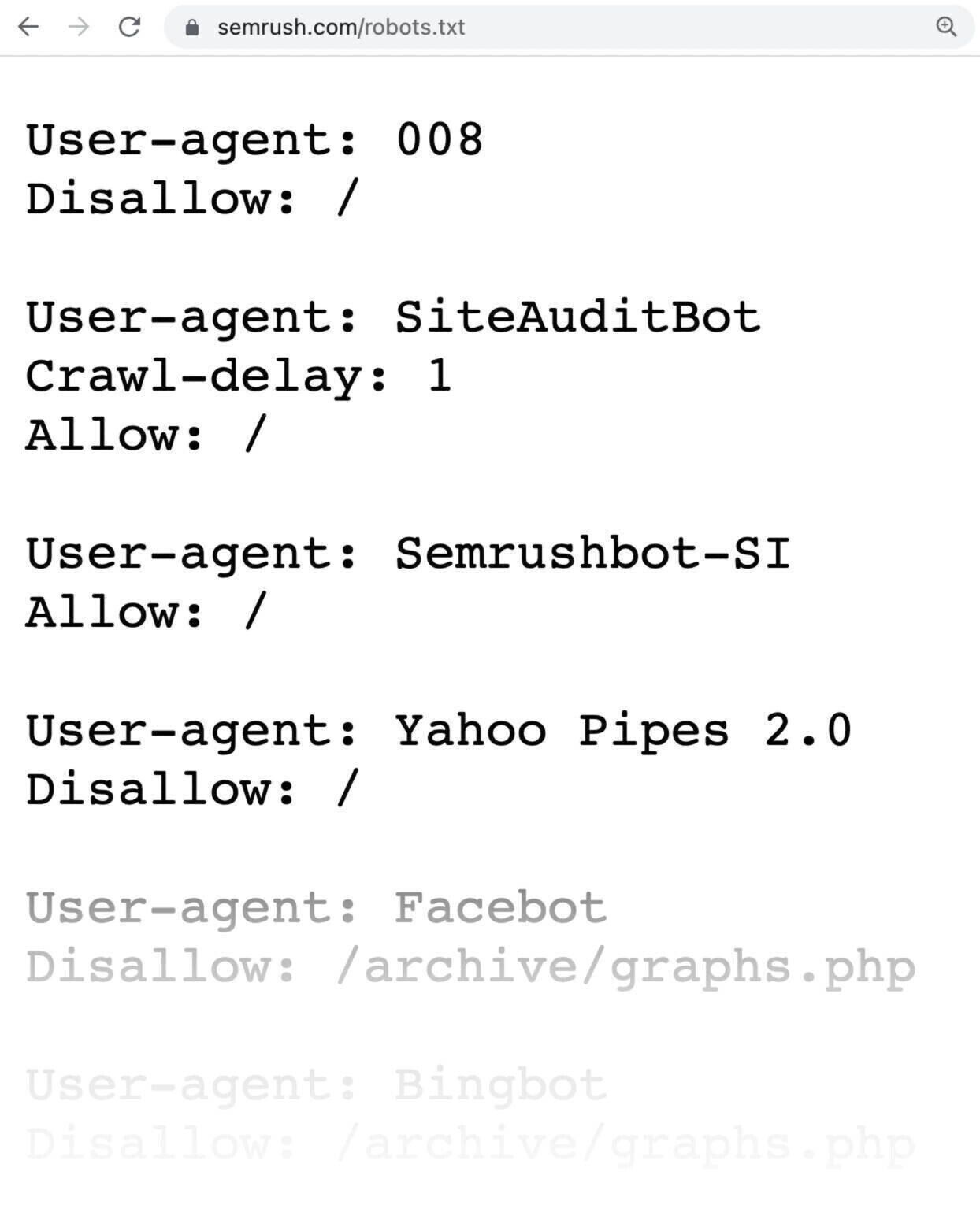
I file robots.txt possono inizialmente sembrare complicati, ma la sintassi (linguaggio informatico) è piuttosto semplice. La approfondiremo più avanti.
In questo articolo parleremo di:
- Perché i file Robots.txt sono importanti.
- Come funzionano i file Robots.txt.
- Come creare un file Robots.txt.
- Le migliori pratiche per il file Robots.txt.
Perché i file Robots.txt sono importanti?
Un file robots.txt aiuta a gestire le attività dei web crawler, in modo che non sovraccarichino il tuo sito web o indicizzino pagine non destinate alla visualizzazione pubblica.
Ecco alcuni motivi per cui dovresti utilizzare un file robots.txt:
1. Ottimizzare il Crawl Budget
Il "crawl budget", o budget di scansione, è il numero di pagine che Google può scansionare sul tuo sito in qualsiasi momento. Questo numero può variare in base alle dimensioni, alla salute e ai backlink del tuo sito.
Il crawl budget è importante perché se il numero delle tue pagine supera il crawl budget del tuo sito, ci saranno pagine del tuo sito che non verranno indicizzate.
E le pagine che non vengono indicizzate non si classificano.
Bloccando le pagine non necessarie con il robots.txt, Googlebot (il crawler di Google) può destinare una parte maggiore del budget di scansione alle pagine importanti del tuo sito.
2. Bloccare le pagine duplicate e quelle non pubbliche
Non è necessario consentire ai motori di ricerca di scansionare tutte le pagine del tuo sito perché non tutte devono classificarsi, come i siti di staging, le pagine interne dei risultati di ricerca, le pagine duplicate o quelle di login.
WordPress, ad esempio, disabilita automaticamente /wp-admin/ per tutti i crawler.
Queste pagine devono esistere, ma non è necessario che vengano indicizzate e trovate dai motori di ricerca. Un caso perfetto è quello di utilizzare il robots.txt per bloccare ai crawler e ai bot l'accesso a queste pagine.
3. Nascondere risorse
In alcuni casi vorrai che Google escluda dai risultati di ricerca risorse come PDF, video e immagini.
Forse vuoi mantenere queste risorse private o far sì che Google si concentri su contenuti più importanti.
In questo caso, l'uso del robots.txt è il modo migliore per evitare che queste pagine vengano indicizzate.
Come funziona un file Robots.txt?
I file robots.txt indicano ai bot dei motori di ricerca quali URL possono scansionare e, soprattutto, quali no.
I motori di ricerca hanno due compiti principali:
- scansionare il web per scoprire i contenuti;
- indicizzare i contenuti in modo che possano essere mostrati agli utenti in cerca di informazioni.
Mentre scansionano i siti, i bot dei motori di ricerca scoprono e seguono i link. Questo processo li porta dal sito A al sito B al sito C attraverso miliardi di link e siti web.
Quando arriva su un sito, la prima cosa che un bot fa è cercare un file robots.txt.
Se lo trova, lo legge prima di fare qualsiasi altra cosa.
Se ricordi, un file robots.txt ha questo aspetto:

La sintassi è molto semplice.
Si assegnano regole ai bot indicando il loro user-agent (il bot del motore di ricerca), seguito dalle direttive (le regole).
Puoi anche utilizzare il carattere dell'asterisco (*) per assegnare le direttive a qualunque user-agent. Ciò significa che la regola indicata si applica a tutti i bot, piuttosto che a uno specifico.
Ad esempio, le istruzioni sarebbero queste se volessi permettere a tutti i bot, tranne DuckDuckGo, di scansionare il tuo sito:

Nota: Un file robots.txt fornisce istruzioni, ma non può farle rispettare. È come un codice di condotta: i bot buoni (come quelli dei motori di ricerca) seguiranno le regole, mentre quelli cattivi (come quelli dello spam) le ignoreranno.
Come trovare un file Robots.txt
Il file robots.txt è ospitato sul tuo server, proprio come qualsiasi altro file del tuo sito web.
Puoi vedere il file robots.txt di un determinato sito web digitando l'URL completo della homepage e aggiungendo /robots.txt, come ad esempio https://semrush.com/robots.txt.

Nota: Un file robots.txt dovrebbe sempre trovarsi nella root del tuo dominio. Quindi, per il sito www.example.com, il file robots.txt si trova all'indirizzo www.example.com/robots.txt. In caso contrario, i crawler penseranno che non ne hai uno.
Prima di imparare a creare un file robots.txt, vediamo la sintassi che contiene.
Sintassi del Robots.txt
Un file robots.txt è composto da:
- uno o più blocchi di "direttive" (regole);
- ognuno con uno specifico "user-agent" (bot del motore di ricerca);
- un'istruzione "allow" o "disallow".
Un blocco semplificato può assomigliare a questo:
User-agent: Googlebot
Disallow: /not-for-google
User-agent: DuckDuckBot
Disallow: /not-for-duckduckgo
Sitemap: https://www.yourwebsite.com/sitemap.xmlLa direttiva User-Agent
La prima riga di ogni blocco di direttive è lo "user-agent", che identifica il crawler a cui sono indirizzate le regole indicate.
Quindi, se vuoi dire a Googlebot di non scansionare la tua pagina di amministrazione di WordPress, ad esempio, la tua direttiva inizierà con:
User-agent: Googlebot
Disallow: /wp-admin/Tieni presente che la maggior parte dei motori di ricerca ha più crawler (per l'indice normale, le immagini, i video e così via).
I motori di ricerca scelgono sempre il blocco di direttive più specifico che riescono a trovare.
Supponiamo di avere tre gruppi di direttive: uno per *, uno per Googlebot e uno per Googlebot-Image.
Se lo user-agent Googlebot-News scansiona il tuo sito, seguirà le direttive di Googlebot.
D'altra parte, lo user-agent Googlebot-Image seguirà le direttive più specifiche di Googlebot-Image.
Qui trovi una lista dettagliata dei web crawler e dei loro diversi user-agent.
La direttiva Disallow
La seconda riga di ogni blocco di direttive è la riga "Disallow".
Puoi avere più direttive "Disallow" che specificano a quali parti del tuo sito il crawler non può accedere.
Una riga "Disallow" vuota significa che non stai vietando nulla, quindi un crawler può accedere a tutte le sezioni del tuo sito.
Ad esempio, se volessi permettere a tutti i motori di ricerca di scansionare il tuo sito nella sua interezza, il tuo blocco avrebbe questo aspetto:
User-agent: *
Allow: /Se invece volessi impedire a tutti i motori di ricerca di scansionare il tuo sito, il blocco avrebbe questo aspetto:
User-agent: *
Disallow: /Le direttive come "Allow" e "Disallow" non sono sensibili alle maiuscole e minuscole, quindi sta a te decidere se usare o meno le maiuscole.
Tuttavia, i valori all'interno di ogni direttiva sono sensibili a questa differenza.
Ad esempio, /photo/ non è la stessa cosa di /Photo/.
Comunque, spesso le direttive "Allow" e "Disallow" sono scritte in maiuscolo perché rendono il file più facile da leggere per le persone.
La direttiva Allow
La direttiva "Allow" permette ai motori di ricerca di scansionare una sottodirectory o una pagina specifica, anche in una directory altrimenti non consentita.
Ad esempio, se vuoi impedire a Googlebot di accedere a tutti i post del tuo blog tranne uno, la tua direttiva potrebbe avere questo aspetto:
User-agent: Googlebot
Disallow: /blog
Allow: /blog/esempio-postNota: Non tutti i motori di ricerca riconoscono questo comando. Google e Bing supportano questa direttiva.
La direttiva Sitemap
La direttiva "Sitemap" indica ai motori di ricerca, in particolare a Bing, Yandex e Google, dove trovare la tua sitemap XML.
Le sitemap generalmente includono le pagine che vuoi far scansionare e indicizzare ai motori di ricerca.
Questa direttiva si trova all'inizio o alla fine del file robots.txt e si presenta in questo modo:
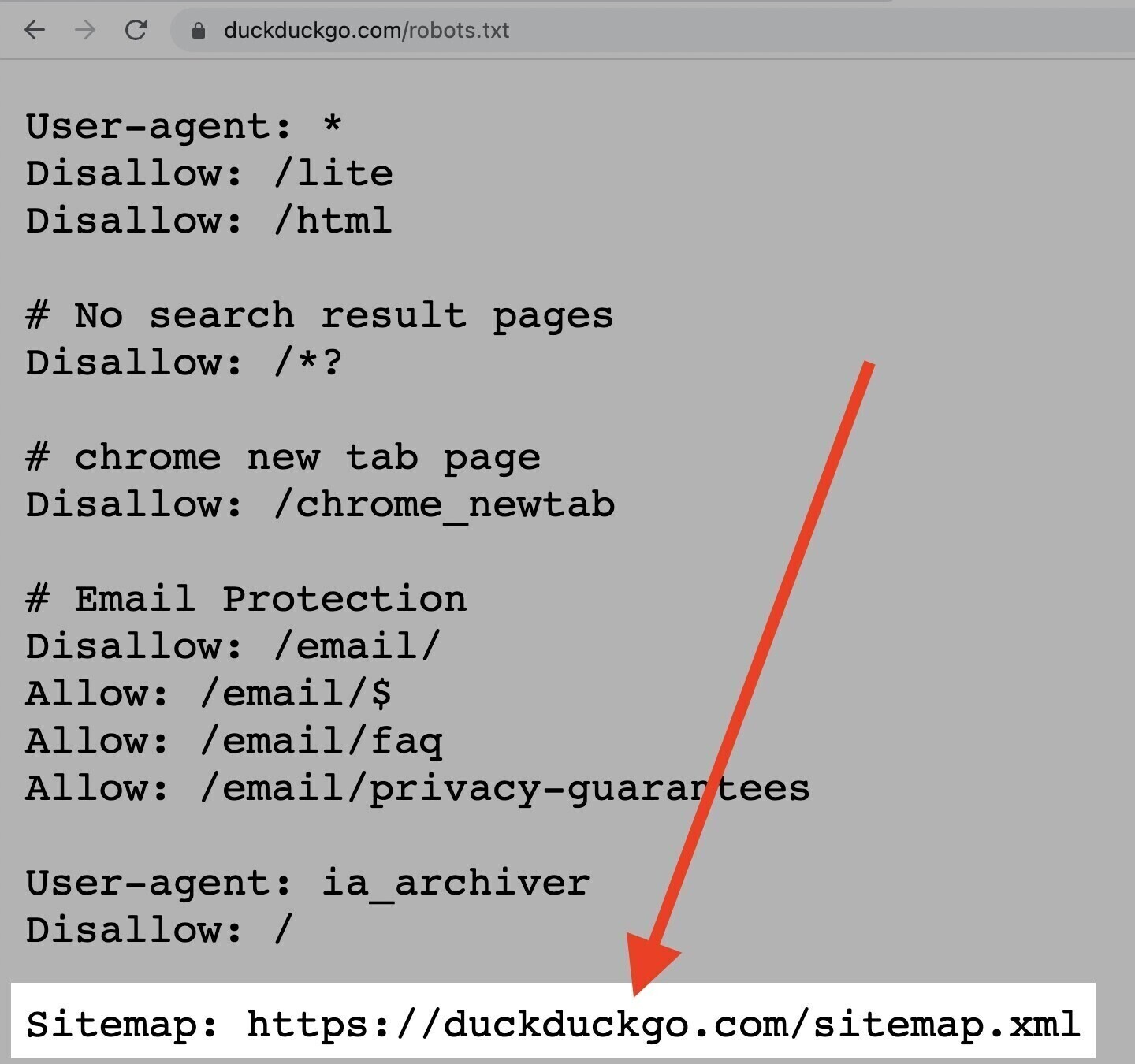
Detto questo, puoi (e dovresti) inviare la tua sitemap XML a ogni motore di ricerca utilizzando i loro strumenti per webmaster.
I motori di ricerca prima o poi scansioneranno il tuo sito, ma l'invio di una sitemap velocizza il processo di scansione.
Se non vuoi farlo, l'aggiunta di una direttiva "Sitemap" al tuo file robots.txt è una valida e rapida alternativa.
La direttiva Crawl-Delay
La direttiva "crawl-delay" specifica un ritardo di scansionamento in secondi. Ha lo scopo di impedire ai crawler di sovraccaricare il server (cioè di rallentare il tuo sito web).
Tuttavia, Google non supporta più questa direttiva.
Se vuoi impostare la velocità di scansione per Googlebot, dovrai farlo in Search Console.
Bing e Yandex, invece, supportano la direttiva crawl-delay.
Ecco come usarla.
Se vuoi che un crawler attenda 10 secondi dopo ogni azione di scansionamento, puoi impostare 10 secondi di ritardo in questo modo:
User-agent: *
Crawl-delay: 10La direttiva Noindex
Il file robots.txt dice a un bot cosa può o non può scansionare, ma non può dire a un motore di ricerca quali URL non indicizzare e mostrare nei risultati di ricerca.
La pagina verrà comunque visualizzata nei risultati di ricerca, ma il bot non saprà cosa contiene, quindi la tua pagina avrà questo aspetto:

Google non ha mai supportato ufficialmente questa direttiva, ma i professionisti SEO credevano che seguisse comunque le istruzioni.
Tuttavia, il 1° settembre 2019, Google ha chiarito che questa direttiva non è supportata.
Se vuoi escludere in modo affidabile una pagina o un file dalla visualizzazione nei risultati di ricerca, evita del tutto questa direttiva e utilizza un meta tag robots noindex.
Come creare un file Robots.txt
Se non hai ancora un file robots.txt, crearne uno è facile.
Puoi utilizzare un generatore di file robots.txt o crearne uno tu stesso.
Ecco come creare un file robots.txt in soli quattro passi:
- Crea un file e nominalo robots.txt.
- Aggiungi delle direttive al file robots.txt.
- Carica il file robots.txt sul tuo sito.
- Testa il tuo file robots.txt.
1. Crea un file e nominalo robots.txt
Inizia aprendo un documento .txt con un qualsiasi editor di testo o browser web.
Nota: non usare un elaboratore di testi (come word) perché questi programmi spesso salvano i file in un formato proprietario che può aggiungere caratteri casuali.
Successivamente, nomina il documento robots.txt. Deve essere chiamato robots.txt per poter funzionare.
Ora puoi cominciare a inserire le direttive.
2. Aggiungi delle direttive al file robots.txt
Un file robots.txt è costituito da uno o più gruppi di direttive e ogni gruppo è composto da più righe di istruzioni.
Ogni gruppo inizia con uno "User-agent" e contiene le seguenti informazioni:
- a chi si applica il gruppo (lo user-agent);
- a quali directory (pagine) o file può accedere lo user agent;
- a quali directory (pagine) o file non può accedere lo user-agent;
- una sitemap (opzionale) per indicare ai motori di ricerca le pagine e i file che ritieni importanti.
I crawler ignorano le righe che non corrispondono a nessuna di queste direttive.
Ad esempio, supponiamo che tu voglia impedire a Google di scansionare la directory /clients/ perché è solo per uso interno.
Il primo gruppo potrebbe essere così formulato:
User-agent: Googlebot
Disallow: /clients/Se hai altre istruzioni come questa per Google, devi inserirle in una riga separata appena sotto, in questo modo:
User-agent: Googlebot
Disallow: /clients/
Disallow: /not-for-googleUna volta terminate le istruzioni specifiche per Google, puoi premere due volte invio per creare un nuovo gruppo di direttive.
Creiamo questo gruppo per tutti i motori di ricerca e impediamo loro di scansionare le tue directory /archive/ e /support/ perché sono private e solo per uso interno.
Il gruppo avrebbe il seguente aspetto:
User-agent: Googlebot
Disallow: /clients/
Disallow: /not-for-google
User-agent: *
Disallow: /archive/
Disallow: /support/Una volta terminato, puoi aggiungere la tua sitemap.
Il tuo file robots.txt finito avrà un aspetto simile a questo:
User-agent: Googlebot
Disallow: /clients/
Disallow: /not-for-google
User-agent: *
Disallow: /archive/
Disallow: /support/
Sitemap: https://www.yourwebsite.com/sitemap.xmlSalva il file robots.txt. Ricorda che deve essere nominato robots.txt.
Nota: I crawler leggono dall'alto verso il basso e seguono il primo gruppo di regole più specifico. Quindi, inizia il tuo file robots.txt prima con gli user-agent specifici e poi passa al carattere asterisco più generale (*) che corrisponde a tutti i crawler.
3. Carica il file robots.txt sul tuo sito
Dopo aver salvato il file robots.txt sul tuo computer, caricalo sul tuo sito e rendilo disponibile per essere scansionato dai motori di ricerca.
Purtroppo non esiste uno strumento universale che possa aiutarti in questo passaggio.
Il caricamento del file robots.txt dipende dalla struttura dei file del tuo sito e dal tuo hosting web.
Cerca online o contatta il tuo provider di hosting per sapere come caricare il tuo file robots.txt.
Ad esempio, puoi cercare "caricare il file robots.txt su WordPress" per ottenere istruzioni specifiche.
Ecco alcuni articoli che spiegano come caricare il file robots.txt nelle piattaforme più diffuse:
- file robots.txt su WordPress;
- file robots.txt su Wix;
- file robots.txt su Joomla;
- file robots.txt su Shopify;
- file robots.txt su BigCommerce.
Dopo aver caricato il file robots.txt, controlla se è visibile a tutti e se Google può leggerlo.
Ecco come fare.
4. Testa il tuo file robots.txt
Per prima cosa, verifica se il tuo file robots.txt è accessibile pubblicamente (cioè se è stato caricato correttamente).
Apri una finestra privata nel tuo browser e cerca il tuo file robots.txt.
Ad esempio: https://semrush.com/robots.txt.
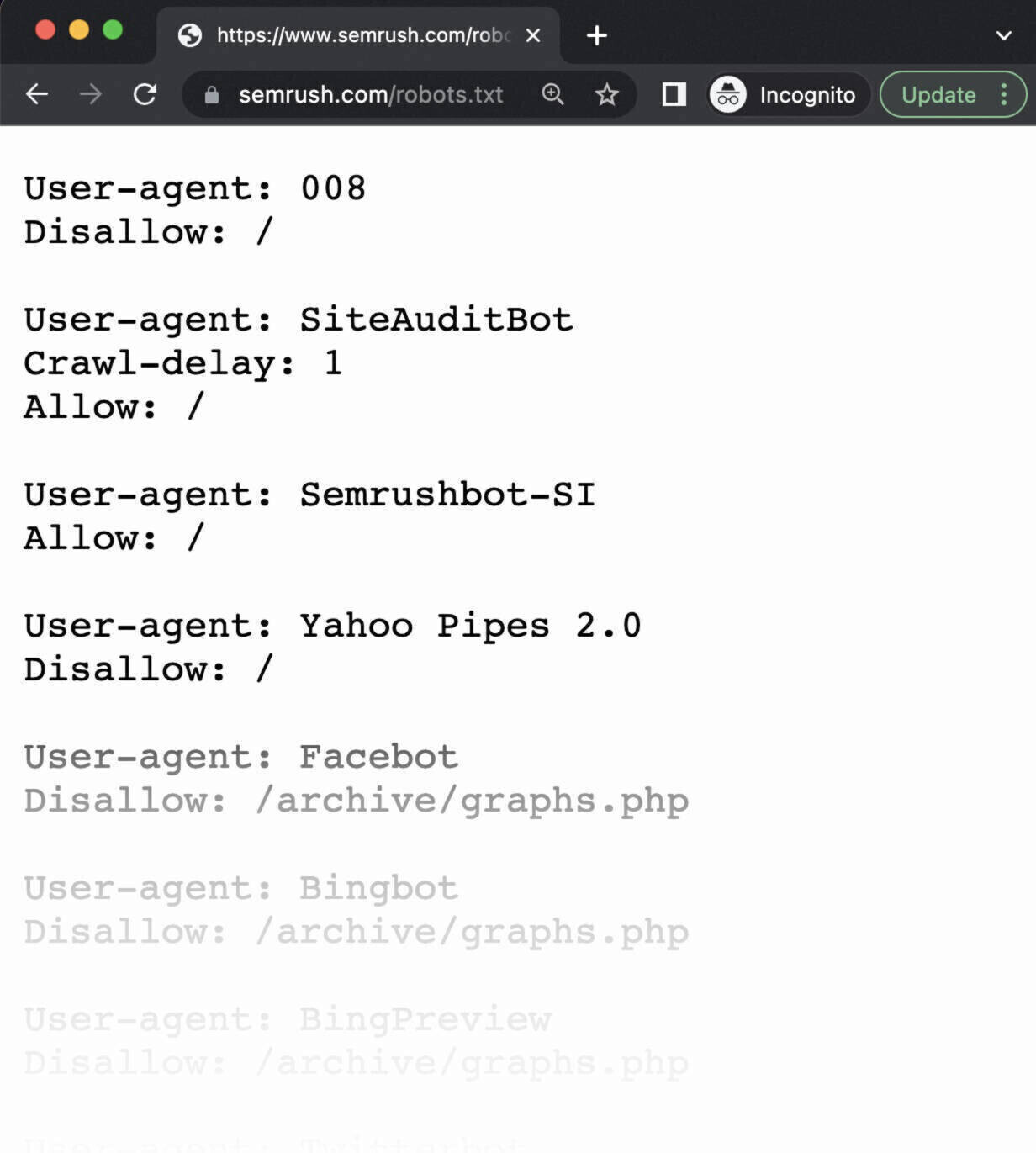
Se vedi il tuo file robots.txt con il contenuto che hai aggiunto, sei pronto a testare il markup (codice HTML).
Google offre due opzioni per testare il markup robots.txt:
- Il Tester del robots.txt in Search Console.
- La libreria robots.txt open source di Google (Avanzato).
Poiché la seconda opzione è più orientata agli sviluppatori avanzati, testiamo il tuo file robots.txt in Search Console.
Nota: Per testare il tuo file robots.txt devi aver configurato un account Search Console.
Vai al Tester del robots.txt e clicca su "Apri il Tester dei file robots.txt".

Se non hai ancora collegato il tuo sito web all'account di Google Search Console, dovrai prima aggiungere una proprietà.

Poi dovrai verificare di essere il vero proprietario del sito.

Se hai già delle proprietà verificate, selezionane una dal menu a tendina sulla homepage del Tester.

Il Tester identificherà tutti gli avvisi relativi agli errori di sintassi e gli errori di logica e li evidenzierà.
Inoltre, ti mostrerà il numero di avvisi ed errori immediatamente sotto l'editor.

Puoi modificare gli errori o gli avvisi direttamente sulla pagina e ripetere il test tutte le volte che è necessario.
Tieni presente che le modifiche apportate alla pagina non vengono salvate sul tuo sito. Lo strumento non apporta alcuna modifica al file reale del tuo sito. Esegue solo dei test sul testo ospitato nello strumento.
Per implementare le modifiche, copia e incolla le stesse nel file robots.txt del tuo sito.
Suggerimento: Imposta controlli di SEO tecnica mensili con lo strumento Site Audit per verificare la presenza di nuovi problemi relativi al tuo file robots.txt. Tenere sotto controllo il file è importante, perché anche piccole modifiche possono influire negativamente sull'indicizzazione del tuo sito.
Clicca qui per vedere lo strumento Site Audit di Semrush.
Le best practice per il file Robots.txt
Tieni a mente queste best practice mentre crei il tuo file robots.txt per evitare gli errori più comuni.
Usa una nuova riga per ogni direttiva
Ogni direttiva deve trovarsi su una nuova riga.
In caso contrario, i motori di ricerca non saranno in grado di leggerle e le tue istruzioni verranno ignorate.
No:
User-agent: * Disallow: /admin/
Disallow: /directory/Sì:
User-agent: *
Disallow: /admin/
Disallow: /directory/Usa ogni User-Agent una volta sola
Ai bot non importa se inserisci lo stesso user-agent più volte.
Tuttavia, se lo inserisci solo una volta, le cose sono più semplici e pulite e si riduce la possibilità di errore umano.
No:
User-agent: Googlebot
Disallow: /esempio-pagina
User-agent: Googlebot
Disallow: /esempio-pagina-2Nota che lo user-agent di Googlebot è elencato due volte.
Sì:
User-agent: Googlebot
Disallow: /esempio-pagina
Disallow: /esempio-pagina-2Nel primo esempio, Google seguirebbe comunque le istruzioni e non scansionerebbe nessuna delle due pagine.
Tuttavia, scrivere tutte le direttive sotto lo stesso user-agent è più pulito e ti aiuta a organizzarti.
Usa l'asterisco per chiarire le indicazioni
Puoi utilizzare il carattere asterisco (*) per applicare una direttiva a tutti gli user-agent e seguire i modelli di URL.
Ad esempio, se vuoi impedire ai motori di ricerca di accedere a URL con determinati parametri, puoi tecnicamente elencarli uno per uno.
No:
User-agent: *
Disallow: /scarpe/vans?
Disallow: /scarpe/nike?
Disallow: /scarpe/adidas?Ma questo metodo è poco efficiente. Puoi semplificare le tue indicazioni con un carattere asterisco.
Sì:
User-agent: *
Disallow: /scarpe/*?L'esempio precedente blocca tutti i bot dei motori di ricerca dallo scansionare tutti gli URL sotto la sottocartella /scarpe/ con un punto interrogativo.
Usa "$" per indicare la fine di un URL
L'aggiunta del carattere "$" indica la fine di un URL.
Ad esempio, se vuoi impedire ai motori di ricerca di scansionare tutti i file .jpg del tuo sito, puoi elencarli singolarmente.
Ma questo metodo non è molto efficiente.
No:
User-agent: *
Disallow: /foto-a.jpg
Disallow: /foto-b.jpg
Disallow: /foto-c.jpgSarebbe molto meglio utilizzare la funzione "$" in questo modo:
Sì:
User-agent: *
Disallow: /*.jpg$Nota: In questo esempio, /dog.jpg non può essere scansionato, ma /cane.jpg?p=32414 sì perché non termina con ".jpg".
L'espressione "$" è una funzione utile in circostanze specifiche come quelle sopra descritte, ma può anche essere pericolosa.
Puoi facilmente sbloccare cose che non intendevi sbloccare, quindi sii prudente quando la applichi.
Usa il cancelletto (#) per aggiungere commenti
I crawler ignorano tutto ciò che inizia con un cancelletto (#).
Per questo motivo, gli sviluppatori utilizzano spesso questo carattere per aggiungere un commento nel file robots.txt. Questo aiuta a mantenere il file organizzato e facile da leggere.
Per inserire un commento, inizia la riga con un il carattere cancelletto #.
In questo modo:
User-agent: *
#Landing Pages
Disallow: /landing/
Disallow: /lp/
#Files
Disallow: /files/
Disallow: /private-files/
#Websites
Allow: /website/*
Disallow: /website/search/*Gli sviluppatori a volte inseriscono messaggi divertenti nei file robots.txt perché sanno che gli utenti li vedono raramente.
Ad esempio, il file robots.txt di YouTube recita:
"Creato in un lontano futuro (l'anno 2000) dopo la rivolta robotica della metà degli anni '90 che ha spazzato via tutti gli esseri umani".

Il robots.txt di Nike recita "just crawl it" (una battuta che strizza l'occhio alla tagline "just do it") e include anche il logo del brand.

Usa file robots.txt separati per i diversi sottodomini
I file robots.txt controllano lo scansionamento solo nel sottodominio in cui sono ospitati.
Quindi, se vuoi controllare il crawling su un altro sottodominio, hai bisogno di un file robots.txt separato.
Questo significa che se il tuo sito principale si trova su dominio.com e il tuo blog si trova sul sottodominio blog.dominio.com, avrai bisogno di due file robots.txt.
Uno per la directory principale del dominio e l'altro per la directory principale del tuo blog.
Continua a imparare
Ora che hai capito bene come funzionano i file robots.txt, ecco altri articoli che puoi leggere per proseguire nella tua formazione: