Una delle questioni più critiche e delicate per chi si occupa di SEO, in particolare di e-commerce, è quella relativa alla gestione delle query strings. Cosa si intende con questo termine?
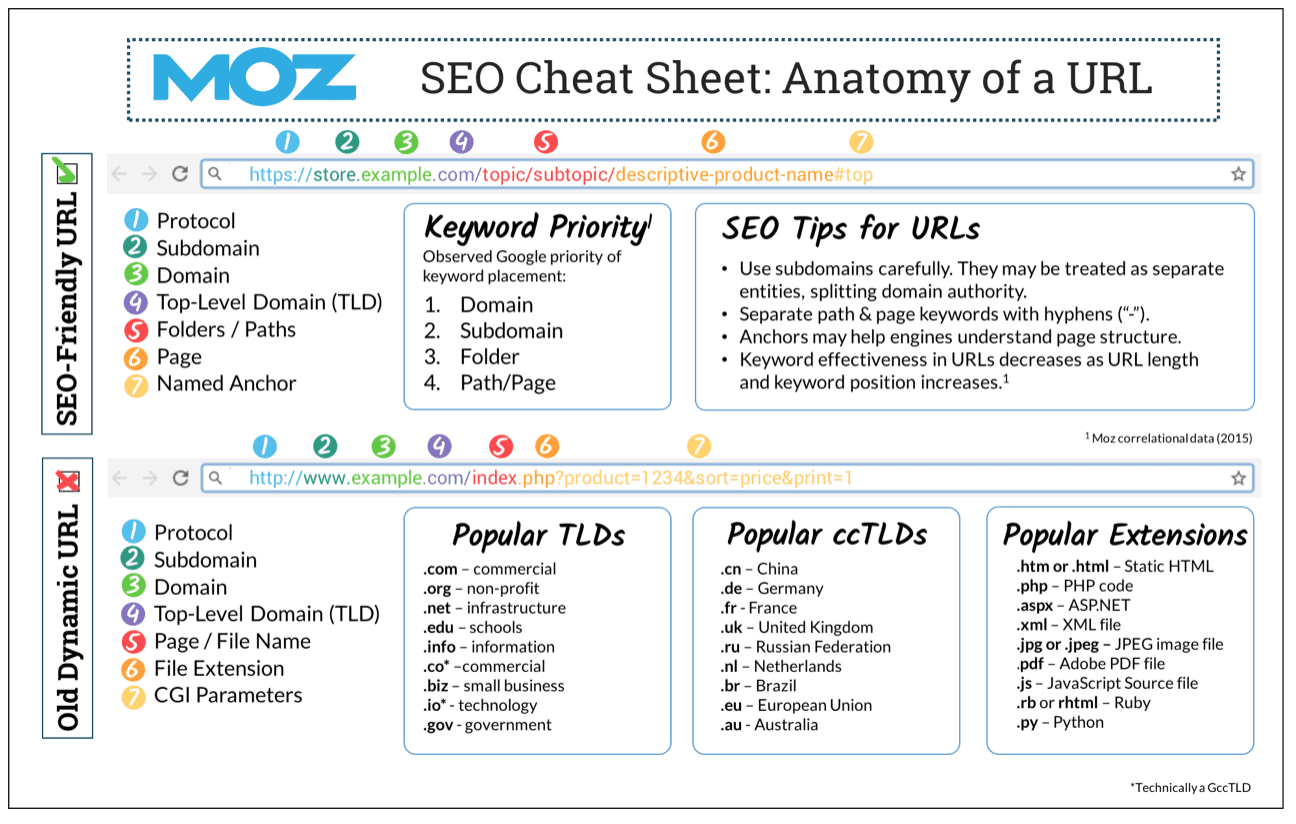
Conosciute anche con l’alias di “stringhe di ricerca”, o con il sinonimo di “URL parametriche”, le query strings sono URL caratterizzate da parametri variabili che seguono un punto interrogativo. Questi indirizzi contengono dei dati che specificano il percorso da compiere per raggiungere la directory nella quale è localizzata la risorsa selezionata dall’utente.
Ad esempio: www.esempio.it/vini?tag_denominazione=Chardonnay&ordinamento=prezzo.
Come si legge una query string?
Se “?” (punto interrogativo) separa l’estensione del file dalla prima variabile disponibile, “&” (simbolo commerciale) separa il valore della prima variabile dal nome della seconda variabile, mentre “=” (simbolo uguale) attribuisce un “left-value” alla variabile a cui è associato.
Le URL parametriche svolgono diverse funzioni all’interno di un sito. Ad esempio, si generano quando l'utente seleziona degli attributi in una pagina di listato dell'e-commerce, oppure quando si utilizzano gli UTM per tracciare le fonti di provenienza del traffico, ma anche quando si decide di applicare la paginazione ad un archivio del sito.
È comprensibile, quindi, che i parametri giochino un ruolo fondamentale nell'esperienza dell’utente e che siano molto amati dagli sviluppatori, tuttavia, sono un vero incubo per noi SEO!
Vi state chiedendo il perché? Vediamolo insieme!
I principali problemi generati dalle stringhe di ricerca
1. I parametri possono generare contenuti duplicati
La navigazione multidimensionale può dare vita a migliaia di varianti della stessa pagina (duplicati), se non si pone attenzione all’ordinamento degli elementi.
Rimanendo sempre sull’esempio di un e-commerce di vini, se selezionassi i filtri “Chardonnay” + “Alto Adige” otterrei l’indirizzo:
www.esempio.it/bianchi.html?tag_denominazione%5B0%5D=Chardonnay&tag_regione%5B0%5D=Alto+Adige
il cui contenuto sarebbe identico a quello ottenuto flaggando i filtri “Alto Adige” + “Chardonnay”:
www.esempio.it/bianchi.html?tag_regione%5B0%5D=Alto+Adige&tag_denominazione%5B0%5D=Chardonnay.
Ma non solo, le URL possono essere diverse a seconda del percorso di navigazione.
Ad esempio, se sul mio sito di vini seleziono la voce “Chardonnay” dal menu di navigazione principale accedo alla pagina di categoria www.esempio.it/bianchi/chardonnay, mentre se entro nella categoria “vini bianchi” e flaggo l’attributo “Chardonnay” ottengo l’URL www.esempio.it/bianchi?tag_denominazione%5B0%5D=Chardonnay.
Le schede prodotto inserite all'interno delle due pagine sono identiche, tuttavia gli indirizzi e gli elementi on-site sono differenti:
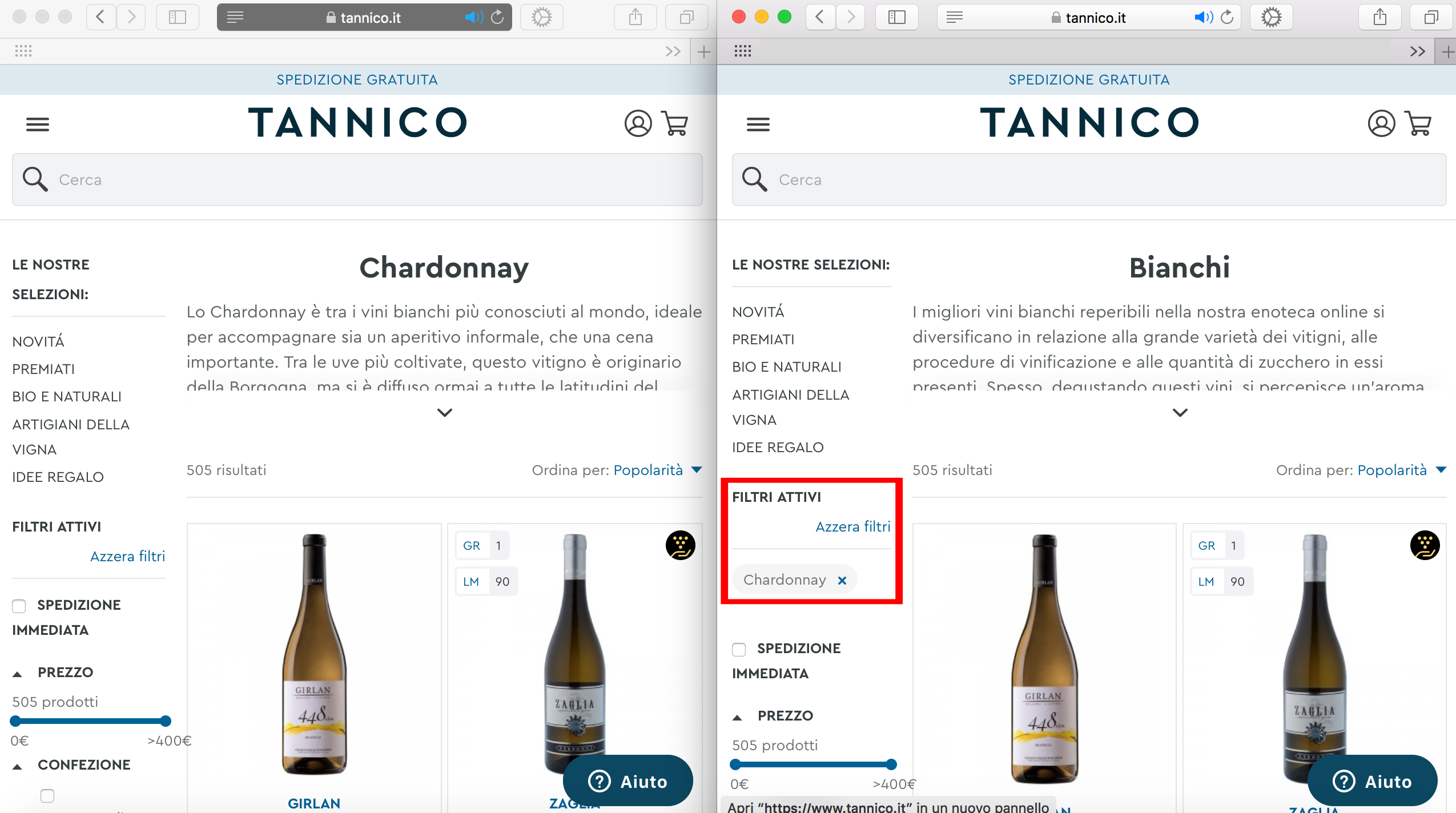
Googlebot, rilevando URL differenti con lo stesso contenuto e non riuscendo a comprendere quale è la versione canonica a cui conferire più valore, potrebbe decidere di indicizzare entrambe le pagine. In questo modo si potrebbe incorrere in un peggioramento delle valutazioni sulla qualità complessiva del sito e a volte anche nel problema della cannibalizzazione delle keywords.
Per approfondire leggi il post: Contenuti duplicati in Ecommerce: 8 casi e loro soluzioni
2. I parametri causano uno spreco di risorse enorme
La scansione di pagine duplicate e di scarso valore determina uno spreco di risorse (crawl budget) enorme ed un sovraccarico del server. Il crawler, infatti, potrebbe avere incertezze su quali siano le pagine corrette da indicizzare. Lo stesso Google a tal proposito afferma:
Overly complex URLs, especially those containing multiple parameters, can cause a problems for crawlers by creating unnecessarily high numbers of URLs that point to identical or similar content on your site. As a result, Googlebot may consume much more bandwidth than necessary, or may be unable to completely index all the content on your site.
3. I parametri influiscono sulla percentuale di clic
Secondo le statistiche, le URL statiche e parlanti sembrerebbero migliorare i risultati in termini di CTR. Gli indirizzi dinamici, invece, potrebbero inficiare sulla percentuale di clic: provate a pensarci, essendo "sgradevoli" e "difficili da leggere", potrebbero apparire poco affidabili all'utente, che, di conseguenza, potrebbe decidere di non aprirle e condividerle sui suoi canali social, sul suo blog, oppure nel suo forum.
4. I parametri non vengono memorizzati nella cache da alcuni server proxy caching
Avete mai provato a testare la velocità del vostro sito con strumenti come Gt Metrix? Allora avrete visto il messaggio “Remove query strings from static resources”.
Le query strings, infatti, non vengono memorizzate nella cache da alcuni server proxy caching, di conseguenza non vengono restituite in maniera statica nel momento in cui l’utente carica il sito.
Dati questi problemi, è davvero necessario utilizzare i parametri URL? Si, come già detto, vengono usati da webmaster e sviluppatori per diversi finalità: vediamo quali!
Le funzioni principali dei parametri SEO delle query strings

-
Ordinare (?sort=): i parametri possono essere usati per l’ordinamento dei risultati in una pagina di listing.
Un esempio può essere l’ordinamento dei prodotti per prezzo: www.esempio.it/vini?ordina=prezzo. La categoria di un eCommerce, con o senza i prodotti ordinati per prezzo, contiene sempre gli stessi elementi. Queste pagine non aggiungono alcun valore, sono duplicati delle pagine canoniche. -
Circoscrivere (?produttore=): un'altra funzione dei parametri è quella di circoscrizione dei risultati per specifiche caratteristiche, come ad esempio taglia, colore, dimensione, peso: www.esempio.it/vini?produttore=falesco. Se la pagina che va a generarsi coincide con ricerche frequenti online preferisco usare una struttura URL a cartelle, invece di un parametro, ad esempio www.esempio.it/vini/produttore/falesco. In alternativa, l'URL parametrica che si verrà a creare andrà correttamente gestita per evitare duplicazioni.
-
Specificare (?id=): un altro utilizzo comune per i parametri è quello di specificare un elemento da visualizzare, che può essere una scheda prodotto, un articolo del blog, una categoria, un profilo utente, ad esempio www.esempio.it/vini?id=123. I parametri che specificano la ricerca devono essere indicizzati, ma solo se definiscono un elemento univoco.
-
Impaginare (?p=): le URL parametriche vengono usate anche per gestire la paginazione, ad esempio www.esempio.it/vini?page=2. Dal mio punto di vista la paginazione dovrebbe essere gestita con gli attributi rel=prev/next (anche se deprecato), oppure con un canonical verso la pagina “view all”.
-
Tracciare (?utm_source): i parametri vengono usati anche per tracciare i canali di provenienza delle visite all’interno delle piattaforme di web analytics, ad esempio www.esempio.it/vini?utm_source=ppc. I parametri di tracciamento non modificano il contenuto della pagina canonica, pertanto questi URL parametrizzati non dovrebbero essere indicizzati dai motori di ricerca.
Tradurre (?lang=): l’utilizzo dei parametri URL rappresenta una alternativa ai ccTLD o ai gTLD dedicati, ad esempio www.esempio.it/vini?lang=it. Sinceramente non utilizzo mai questo metodo di traduzione, per i miei siti, ma mi è capitato di incontrare competitors che utilizzano questo metodo. Detto questo, qual è il modo migliore di gestire questi parametri di traduzione per la SEO? Ovviamente i parametri di traduzione devono essere lasciati indicizzare se si vuole far trovare il sito tra i risultati di ricerca!
Per approfondire leggi il post: Sito web internazionale: meglio un TLD localizzato o uno generico?
Come possono essere gestite le query strings?

Esistono diverse soluzioni per gestire i parametri URL:
Limitare l'uso di parametri inutili
Se ti appresti a rifare un sito, la soluzione è semplice: evita più possibile l’utilizzo di parametri. Con la tecnica dell’URL rewriting potresti programmare il server a leggere gli URL dinamici, riscrivendoli in una forma funzionale al sito web.
Se, invece, hai un sito e vuoi semplicemente migliorare la situazione, potresti farti aiutare da uno sviluppatore per individuare tutte le URL che non hanno più una funzione specifica, che hanno valore vuoto, che hanno lo stesso nome e valore diverso e di conseguenza possono essere semplicemente eliminate. Inoltre, potresti chiedergli di scriverti uno script per dare un ordine coerente ai parametri, indipendentemente dal modo in cui l'utente decide di selezionarli.
I vantaggi di questa soluzione:
-
Consente di migliorare il crawl budget
-
Riduce il problema della duplicazione dei contenuti
-
Consolida il page rank in un numero minore di pagine
Ci sono anche degli svantaggi: oltre a non essere di facile implementazione, da solo non basta per risolvere il problema, ma deve essere associato ad una o più soluzioni alternative. Infatti, non impedisce la duplicazione dei contenuti, non consolida il page rank e può portare a problemi di contenuto sottile.
Usare il tag rel=canonical
Il canonical è un tag che definisce l’URL canonico di riferimento, che i motori di ricerca devono prendere in considerazione in fase di scansione, indicizzazione e posizionamento di una risorsa.
Generalmente viene utilizzato quando ci si trova davanti a due contenuti identici, ad esempio:
www.esempio.it/vini?produttore=falesco vs www.esempio.it/vini/produttore/falesco
Il motore di ricerca scansione entrambe le URL, ma grazie al canonical consoliderà i segnali di ranking verso l'indirizzo canonico. È accettato da tutti i motori di ricerca e dovrebbe essere il primo metodo scelto per la gestione dei parametri del proprio sito, visto che è di facile implementazione.
Tuttavia questa soluzione, presenta anche degli svantaggi:
-
Non viene interpretato come una direttiva, ma come un suggerimento.
-
Non può essere applicato a tutte le tipologie di query strings.
-
Non impedisce ai motori di ricerca di sprecare crawl budget.
Usare il tag noindex
Il secondo suggerimento è quello di impostare una direttiva noindex per qualsiasi pagina basata su parametri, che non aggiunge valore SEO. Questo tag, infatti, può essere implementato con facilità e impedisce ai motori di ricerca di indicizzare la pagina, evitando la nascita di problemi di contenuto duplicato.
Tuttavia anche questa modalità ha i suoi contro:
-
Non viene interpretato come una direttiva, ma come un suggerimento.
-
Non impedisce ai motori di ricerca di eseguire la scansione degli URL.
-
Non impedisce ai motori di ricerca di sprecare risorse durante la scansione.
-
Non consolida il pagerank delle pagine.
Usare il nofollow sui link interni alle sfaccettature indesiderate
Un modo per risolvere il problema dello spreco delle risorse di scansione consiste nel marcare tutti i collegamenti interni alle sfaccettature indesiderate con il rel=nofollow. Ad esempio, tramite questo markup potremmo evitare che Google visiti qualsiasi pagina con due o più filtri selezionati e che trasferisca PageRank. Attenzione però, quei link sono inseriti altrove (senza no follow) oppure all'interno della sitemap.xml, quell'URL verrà scantinato e indicizzato.
Sfortunatamente, però, il "nofollow" non risolve completamente il problema:
-
Non impedisce ai motori di ricerca di indicizzare i contenuti duplicati.
-
Se l'URL è linkata da altre parti (es. nella sitemap.xml) verrà comunque scansionata e indicizzata.
Per approfondire leggi il post: Link Dofollow vs nofollow: cosa sono e quando usarli
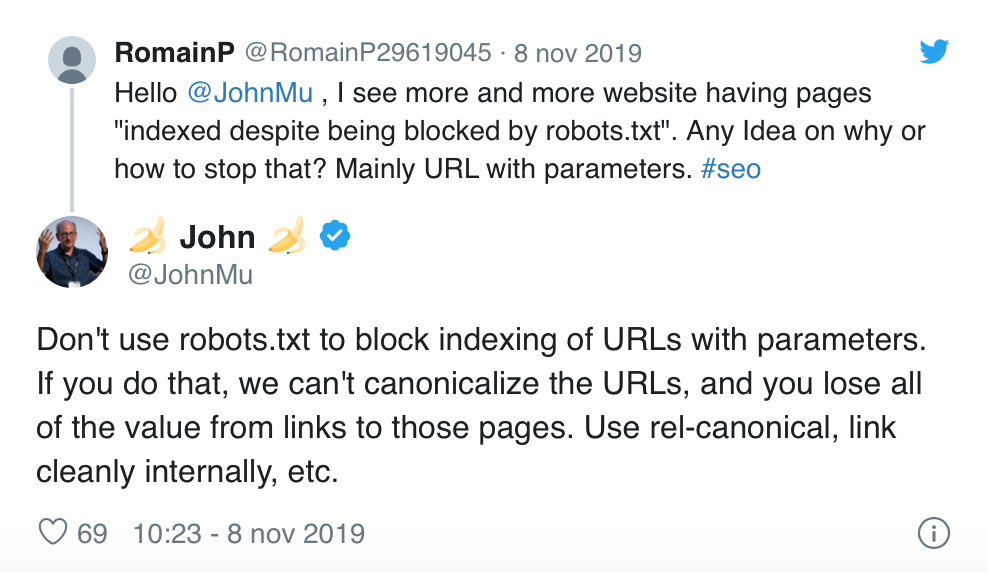
Usare il robots.txt
Il file robots.txt serve ai motori di ricerca per capire se ci sono delle aree del sito a cui si vuole impedire o consentire la scansione. È possibile bloccare l'accesso del crawler ad alcuni (o tutti) gli URL basati su parametri, per consentire un uso più efficiente del budget di scansione ed evitare l’insorgenza di contenuti duplicati.
Questa soluzione, ovviamente, ha dei contro:
-
Non viene interpretato come una direttiva, ma come un suggerimento.
-
Anche se i bot “rispettassero” l’istruzione di non effettuare la scansione di specifiche pagine, queste potrebbero comunque essere indicizzate, senza la descrizione.
-
Non consente la lettura di tag (es. canonical e noindex) applicati alla pagina.
Ecco cosa ha detto John Mueller in un tweet a tal riguardo:
La stessa cosa è stata ribadita in un Hangout per i webmaster di Google (al minuto 19.20).
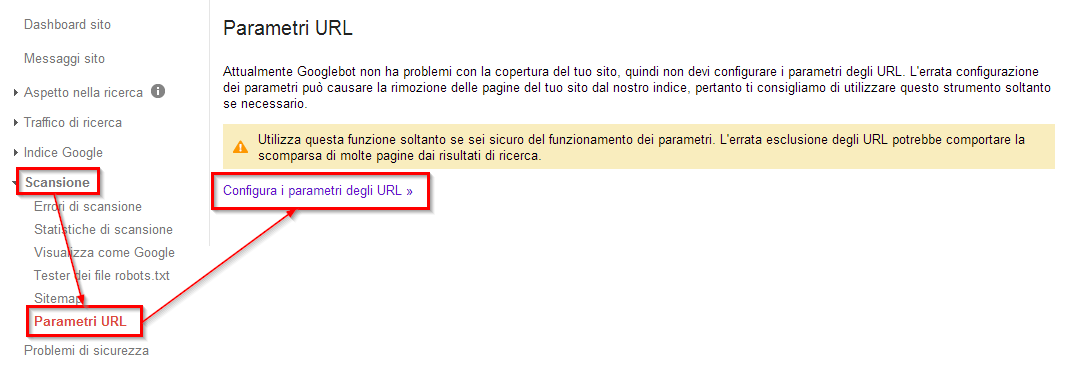
Gestire i parametri nella GSC (Google Search Console)
All'interno della Google Search Console esiste una sezione dedicata alla gestione dei parametri, dove è possibile spiegare a Googlebot le singole funzioni delle stringhe di ricerca. È possibile bloccare o non bloccare la scansione di specifici parametri, ma anche sottoporre a scansione solo URL con determinati valori (ad esempio è possibile specificare che il parametro orderBy serve per ordinare i risultati di ricerca e non è da indicizzare).
Questo strumento andrebbe utilizzato solo in due circostanze: un sito con oltre mille pagine e un numero elevato di pagine duplicate in cui sono diversi soltanto i parametri URL. Non richiede la presenza di uno sviluppatore, tuttavia è importante fare attenzione nell'utilizzo di questo tool, perché un errore potrebbe generare danni al sito e al suo posizionamento nella ricerca.
Gli svantaggi:
-
Non viene interpretato come una direttiva, ma come un suggerimento.
-
Non consolida i segnali di classifica.
-
Funziona solo per Google e non per gli altri motori di ricerca.
Come si comportano i grandi eCommerce nella gestione dei parametri URL?
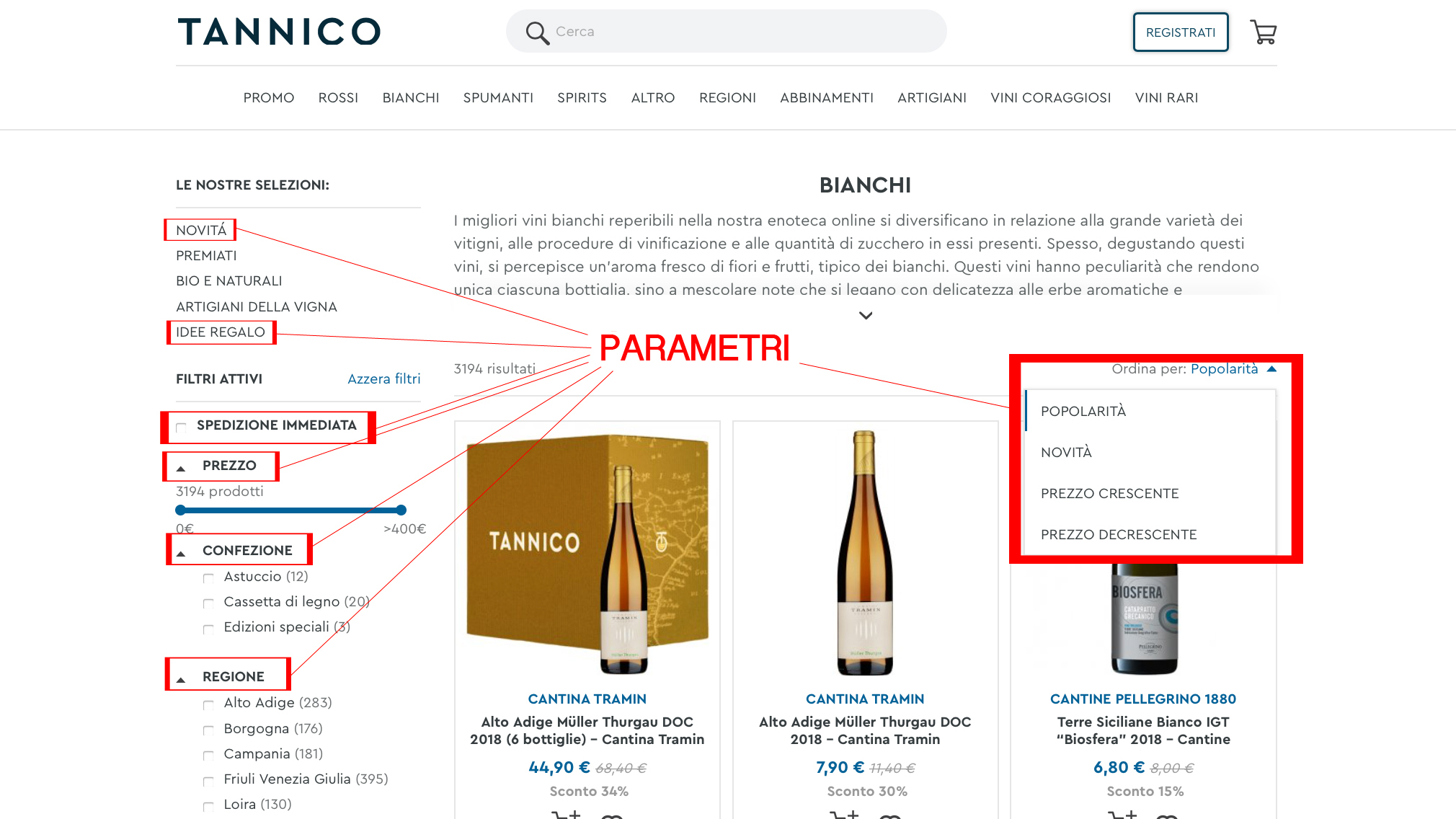
Ogni eCommerce, nella gestione delle query strings, si comporta in modo differente. Porto ad esempio l'analisi di due grandi portali: Tannico (già citato nel resto dell’articolo) e Zalando.
Tannico utilizza URL parametriche per le pagine relative alle novità, alle idee regalo, tutti i filtri di circoscrizione (es. spedizione immediata, prezzo, confezione, regione, etc.) e di ordine (es. popolarità, novità, prezzo crescente, prezzo decrescente) e la combinazione di filtri.
Le voci di menu e le restanti selezioni (es. premiati, bio e naturali, artigiani della vigna) utilizzano URL statiche:
È stato inserito un disallow dei filtri all’interno dei robots.txt:

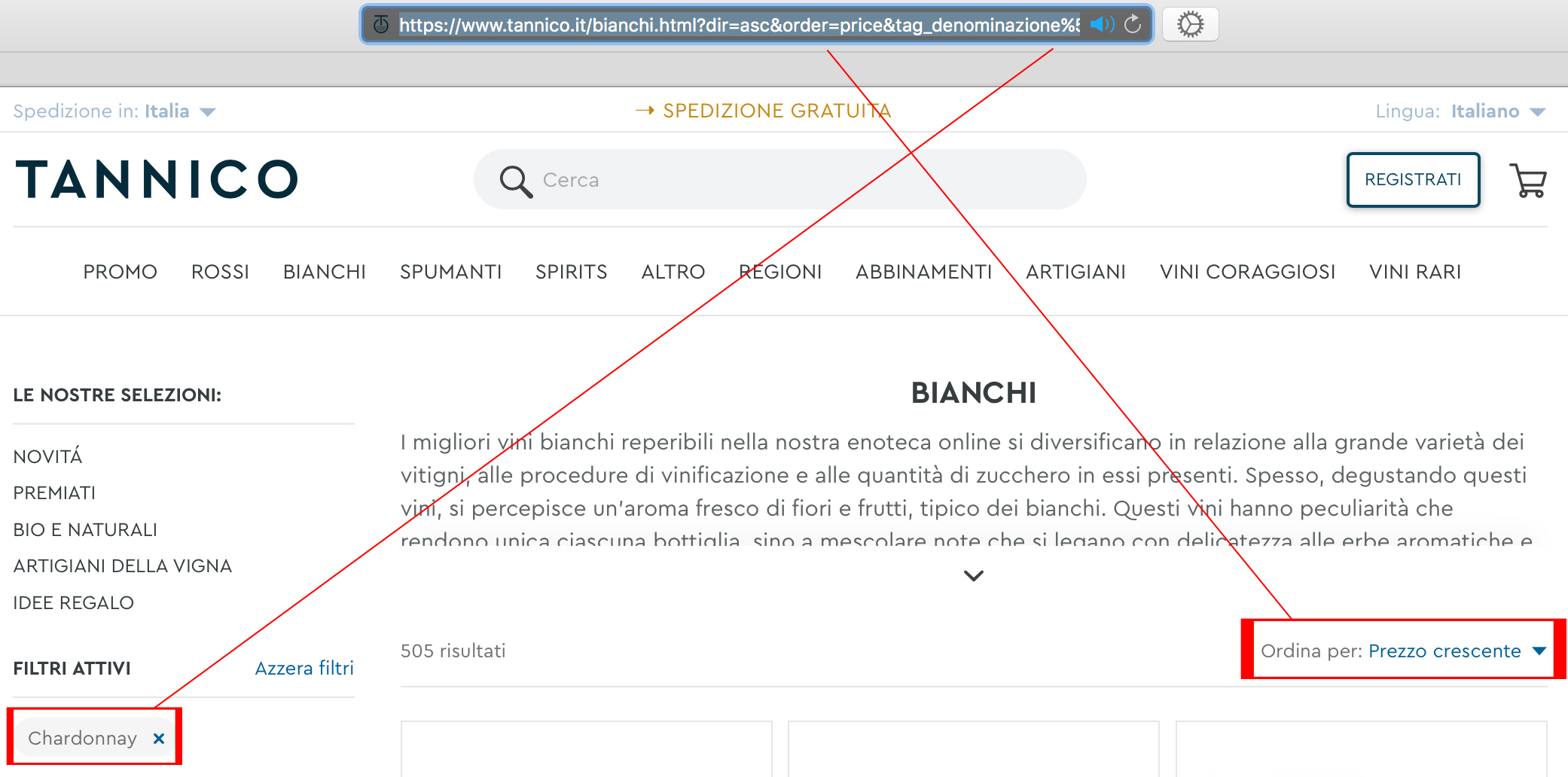
È stata applicata una regola di ordinamento nei filtri, infatti prevale l’ordinamento dei risultati rispetto alla circoscrizione. Indipendentemente dall’ordine in cui si selezionano gli attributi “Chardonnay” e “prezzo crescente” l’URL restituita è: www.tannico.it/bianchi/chardonnay.html?dir=asc&order=price&tag_denominazione%5B0%5D=Chardonnay
Non è stato applicato il rel=canonical sui duplicati, ad esempio: www.tannico.it/bianchi/chardonnay.html e www.tannico.it/bianchi/bio-e-naturali.html?tag_denominazione%5B0%5D=Chardonnay.
Il risultato delle scelte di gestione delle query strings di Tannico è che nelle SERP si sono indicizzate molte combinazioni di parametri, che riportano title e description duplicati:
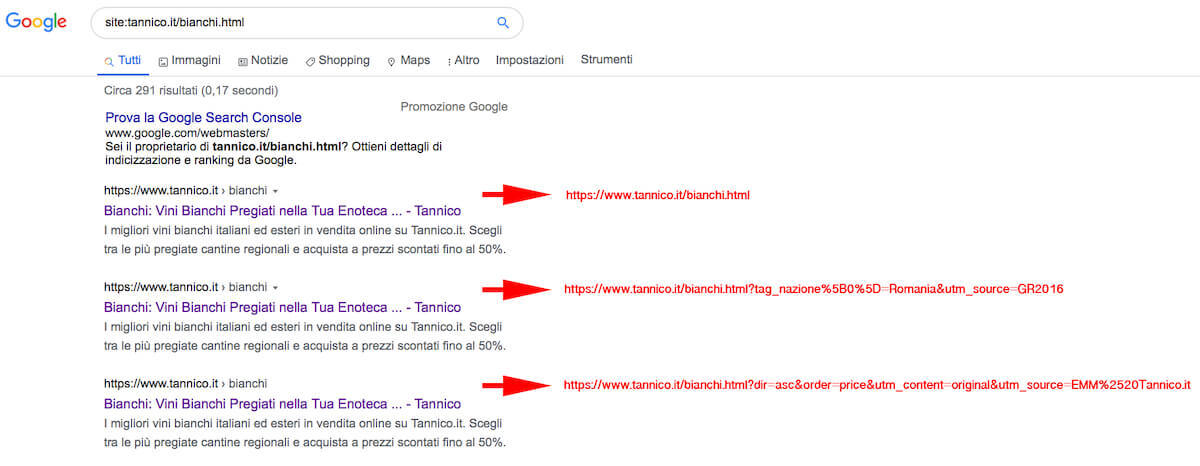
Cliccando sul secondo risultato dell'immagine viene restituita l’URL della pagina di vini bianchi filtrati per la regione “Romania” che per altro è priva di prodotti.
Zalando, invece, utilizza URL parametriche per i filtri di ordine e quasi tutti i filtri di circoscrizione (es. prezzo, materiale, sostenibilità, fantasia, occasione, collezione, stile, etc.), mentre targettizza le long tail, rendendo statiche le pagine di filtro relative a colore, brand e taglia, le quali hanno meta tag e un testo custom:
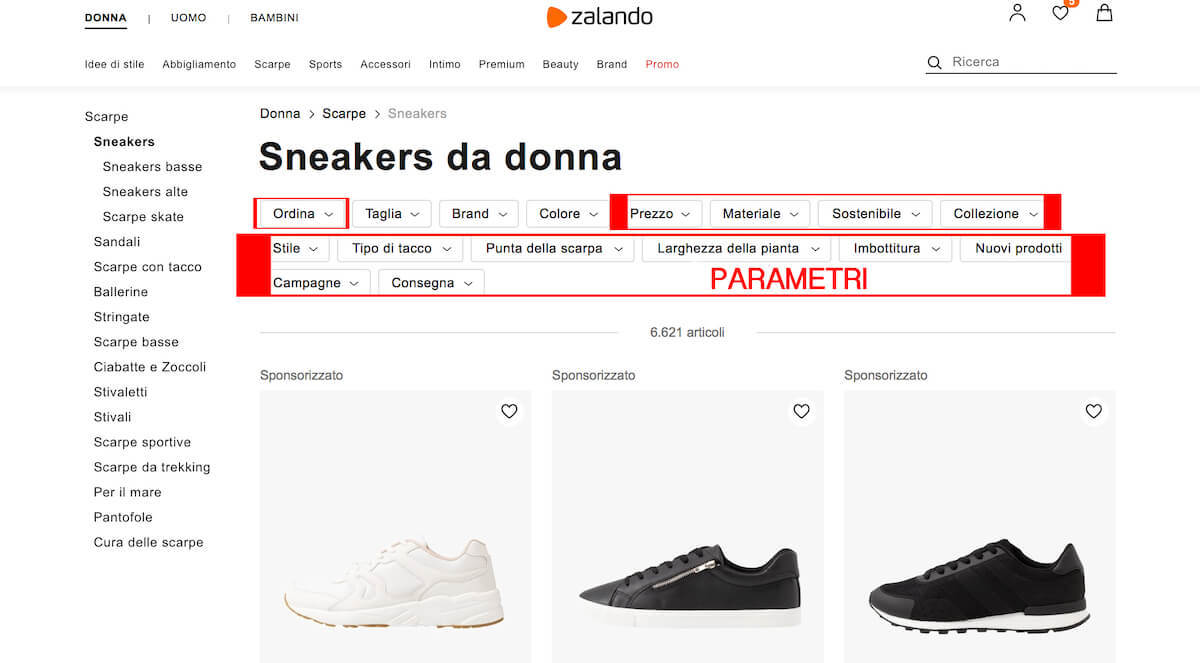
Ad esempio: se sono nella categoria “scarpe donna” e seleziono il filtro “Nike” ottengo la pagina www.zalando.it/scarpe-donna/nike/, che ha titolo, title, description e testo personalizzati:
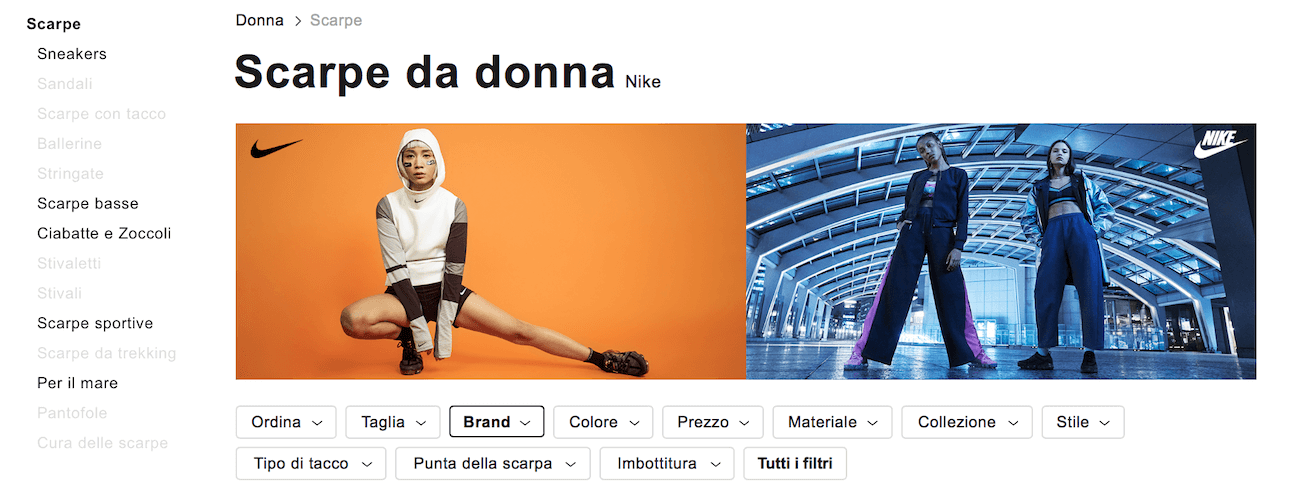

Vuoi saperne di più? Leggi il post: Come scrivere title tag e h1 unici e ottimizzati
È stata applicata una regola di ordinamento nei filtri, infatti prevale la circoscrizione, rispetto all’ordinamento dei risultati, es. www.zalando.it/scarpe-donna/?upper_material=a---costine&order=price&dir=desc.
Mentre, se seleziono un attributo (es. Nike) + un filtro d’ordine (es. prezzo ascendente) ottengo la pagina www.zalando.it/scarpe-donna/nike/?order=price&dir=asc, la quale contiene un canonical verso la pagina www.zalando.it/scarpe-donna/nike/.
Non sono stati applicati disallow ai filtri nel robots.txt. Dando un’occhiata alle SERP, a differenza del caso precedente, non appaiono indicizzate URL parametriche, ma le singole pagine, con meta tag custom:
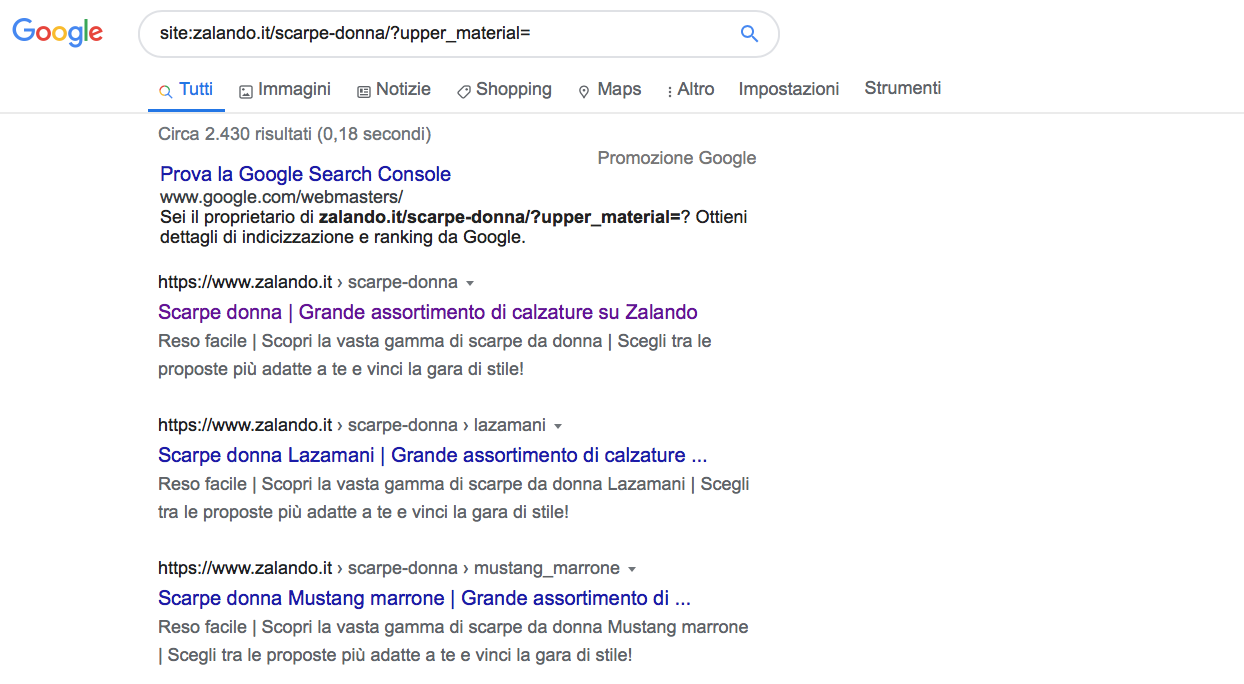
Conclusioni
Ogni modalità di gestione dei parametri ha i suoi pro
e i suoi contro: nessuno conosce la "formula segreta".
Anche John Mueller, nell’Hangout citato in precedenza, afferma che non esiste una modalità giusta o sbagliata per la risoluzione del problema con le stringhe di ricerca, ma che è necessario fare un'attenta valutazione sulla base delle caratteristiche del proprio sito, e che probabilmente potrebbe essere necessario usare una combinazione delle soluzioni qui sopra citate.
Generalmente io mi muovo in questo modo:
-
Durante l’analisi del sito eseguo una veloce ricerca delle parole chiave per capire quali pagine dovrebbero avere URL statici, e quali potrebbero rimanere semplici parametri.
-
Per gli URL basati su parametri faccio implementare regole di ordinamento coerenti, che utilizzano le chiavi una sola volta, e impediscono valori vuoti. Se necessario, utilizzo il rel=canonical per gestire i duplicati, oppure il noindex per escludere risultati inutili e il nofollow per non consentire al motore di ricerca di seguire le risorse indesiderate. Inoltre controllo che sitemap.xml e robots.txt siano correttamente configurati.
-
Imposto correttamente la sezione "parametri URL" nella Google Search Console, per aiutare i motori di ricerca a comprendere la funzione di ciascun elemento.
E voi? Come gestite le query strings dei vostri siti?
Lasciatemi, come sempre, il vostro commento qui sotto!