
SEO & JavaScript: a che punto siamo?
L'8 maggio scorso Google ha ospitato, come ogni anno, il Google I/O 2018, una conferenza rivolta - soprattutto -agli sviluppatori e incentrata sullo sviluppo di applicazioni web con le moderne tecnologie Google.
Alcuni dei contenuti presentati, tuttavia, non sono stati pensati esclusivamente per gli sviluppatori: Google ha infatti indicato quali presentazioni sarebbero state rilevanti per ottenere approfondimenti tecnici lato SEO.
Una delle presentazioni più attese è stata sicuramente quella riguardante l’ottimizzazione SEO dei siti web basati su Javascript. Negli ultimi tempi c’è stato un gran fervore intorno a questo argomento e diversi SEO - uno su tutti Bartosz Góralewicz con il suo esperimento di scansione e indicizzazione di diversi framework Javascript - si sono scervellati per capire come gestire una situazione in cui non si abbia a che fare con un sito in puro e semplice HTML.
Google non aveva ancora rilasciato guide linea ufficiali al riguardo, ma si era limitato ad affermare:
"in linea generale, siamo in grado di effettuare il rendering e capire le pagine web come i moderni browser”
(SPOILER ALERT: sì, come i moderni browser del 2015..! :D). Finalmente, durante una delle presentazioni all'I/O 2018,John Mueller e Tom Greenaway hanno hanno rivelato qualche informazione in più riguardo a come Google vede e indicizza il web, e soprattutto, condiviso le best-practices per far sì che siti e applicazioni web che utilizzano framework JavaScript siano correttamente indicizzabili.

Trovi il video originale a questo link - di seguito i punti chiave e i passaggi più importanti della presentazione.
Google e Javascript
Tom Greenaway e John Müller hanno parlato inizialmente dei moderni siti web basati su JavaScript che utilizzano framework come Angular, Polymer, React o Vue.js. Sebbene questi framework rendano le cose più semplici per gli sviluppatori, possono rendere più difficile per i motori di ricerca la scansione e l'indicizzazione delle pagine web, soprattutto se viene utilizzata un'applicazione a singola pagina (SPA - Single Page Application, dove all’interno di una singola pagina, vengono caricate viste diverse in base all’interazione dell’utente con la pagina stessa), di fatto priva di contenuto HTML.
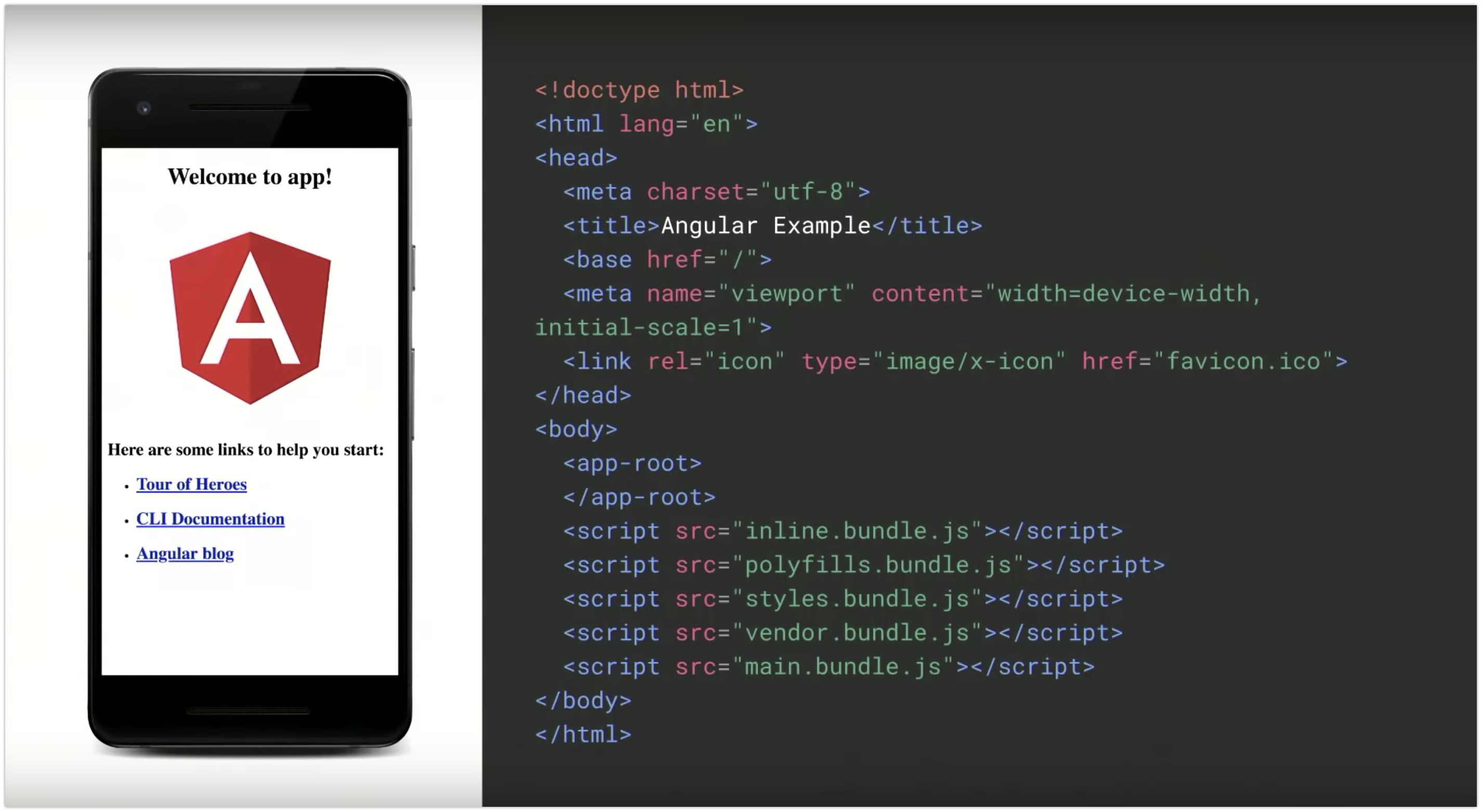 Nel codice non c'è traccia del contenuto - immagini, link, testo - che vediamo nell'immagine a sinistra.
Nel codice non c'è traccia del contenuto - immagini, link, testo - che vediamo nell'immagine a sinistra.
Siti in Javascript: una sfida per Google
Googlebot ha trovato oltre 130 trilioni di documenti sul web (dati luglio 2016). Data la scala del web, l'indicizzazione di tutto il suo contenuto è un compito molto complesso.
Affinché Google possa eseguire la scansione di una pagina, sono necessarie le seguenti condizioni:
-
URL raggiungibili: aggiungi un semplice file di testo, il robots.txt, al dominio di primo livello del tuo sito web, che specifichi quali URL scansionare e quali ignorare, e che contenga anche un link alla sitemap (Qui Tom Greenaway ribadisce come non vi sia alcuna garanzia che questi URL vengano effettivamente sottoposti a scansione; la sitemap è “solo uno dei segnali che i crawler di ricerca prendono in considerazione”.)
-
Contenuti canonici: Google deve capire quale URL è l'originale tra un set di duplicati, e lo può fare grazie alla presenza del canonical tag, che consente ai documenti duplicati di comunicare ai crawler dove risiede la fonte originale e autorevole del contenuto.
-
URL puliti: AJAX ha complicato la possibilità di avere URL puliti, perchéle pagine web potevano eseguire JavaScript che poteva ottenere nuovi contenuti dal server senza ricaricare la pagina web.

Fu quindi inventato il “fragment identifier” per linkare direttamente a sottosezioni di una pagina e, dopo di esso, fu introdotto anche l’hashbang (!#) - per distinguere un URL tradizionale che usa il fragment identifier per linkare alle sotto-sezioni di una pagina da un fragment identifier utilizzato da JavaScript per linkare direttamente a una pagina.
Google consiglia di utilizzare la History API, in quanto ci dà il meglio di entrambi i mondi: contenuti caricati in modo dinamico con URL puliti e tradizionali.
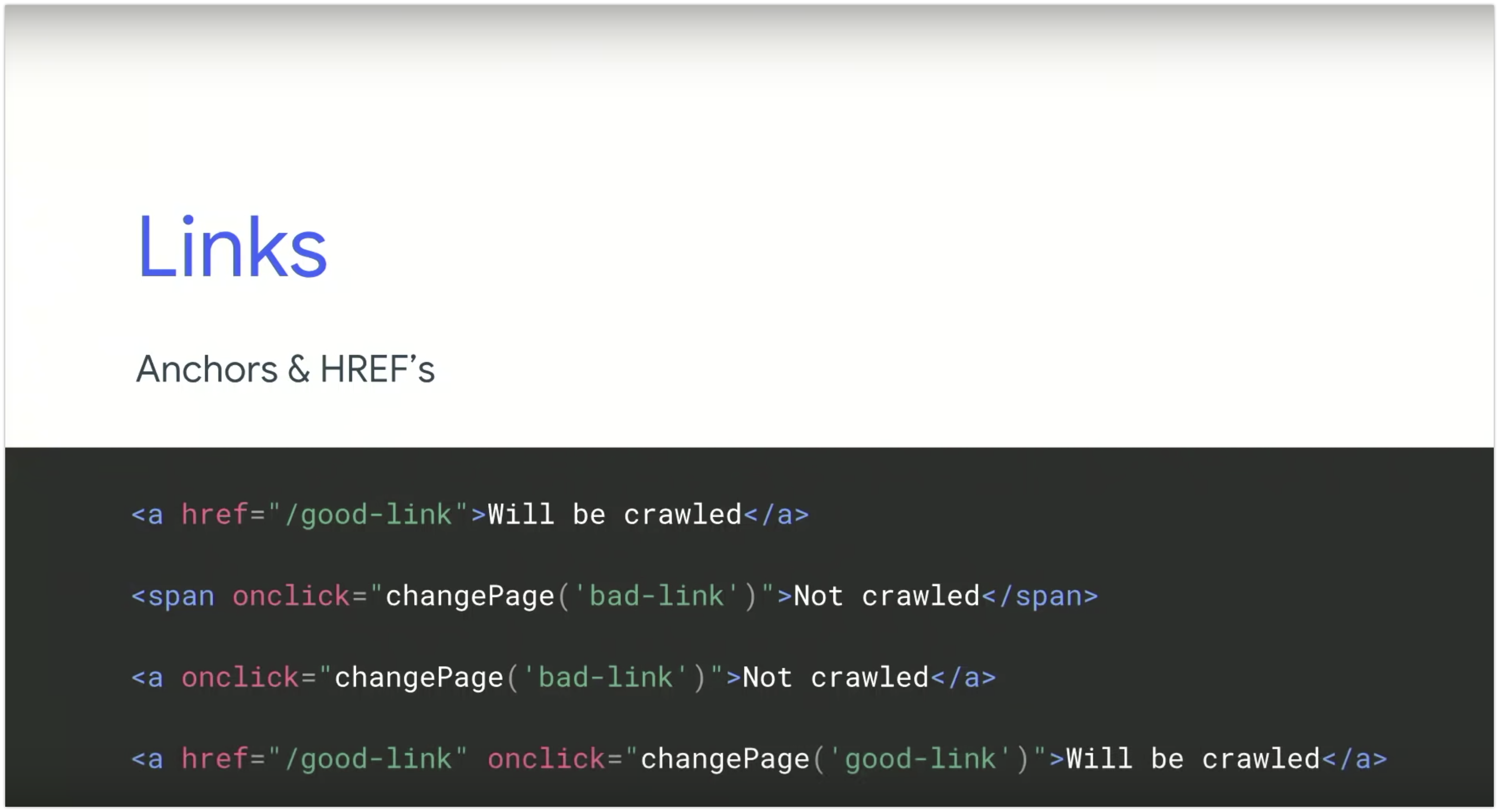
Come trova i link Google?
Google segue solo ed esclusivamente le anchor texts con attributi HREF. Stop. Google non simula la navigazione di una pagina per trovare i link. Puoi vedere dall'esempio qui sotto quali link verranno scansionati e quali no.
Scansione, rendering (!) e indicizzazione
Google vuole essere in grado di trovare - idealmente - tutti i contenuti sul tuo sito web.
Il contenuto principale della pagina include tutto il testo, le immagini, i video e persino gli elementi nascosti, come i dati strutturati. In altre parole, l'HTML della pagina. Ma non dimenticare quel contenuto che hai scaricato in modo dinamico: Google afferma che potrebbe valere la pena indicizzarlo, come i commenti di Facebook o Disqus.
Ma per poter vagliare l'HTML per indicizzare la pagina, è necessario prima di tutto che l'HTML sia disponibile. Ma come abbiamo visto, con i framework JavaScript non è sempre così: Google deve quindi inserire un passaggio tra la scansione e l'indicizzazione: l’attività di rendering.
Cosa significa per i siti in Javascript?
Se Google non ha disponibile l'HTML della pagina, deve prima effettuare il rendering. Dopo di che, Google vuole indicizzare il contenuto per mantenere l'indice di ricerca di Google il più fresco possibile. Tuttavia, il ciclo scansione - rendering - indicizzazione avviene istantaneamente solo se tutto il contenuto è renderizzato sul server e lo è per intero quando viene sottoposto a scansione (!!!).
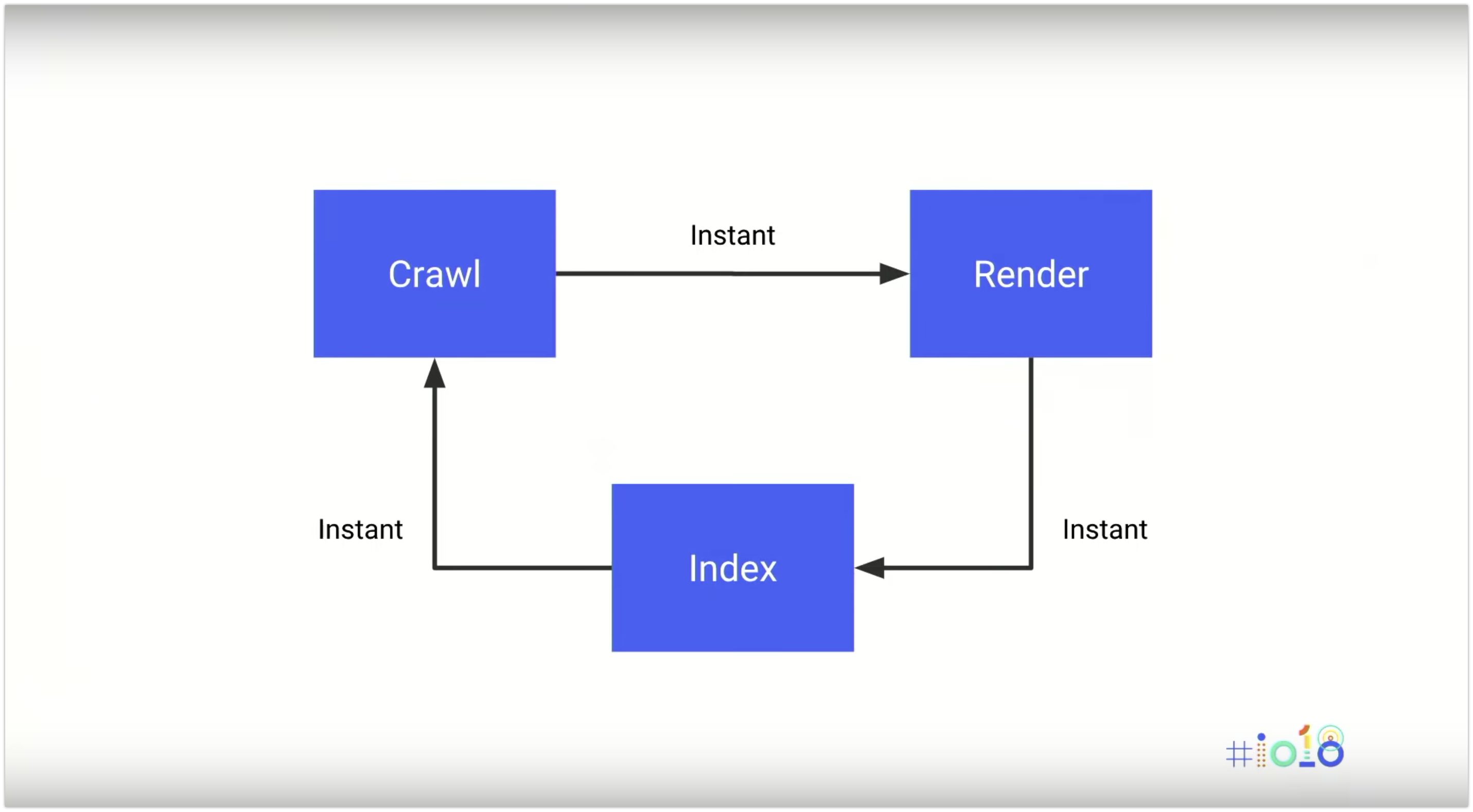
Googlebot utilizza il proprio renderer (in realtà è l’indexer - Caffeine - che esegue il rendering - confermato da Gary Illyes su Twitter), e lo esegue quando incontra pagine web con JavaScript. Ma poiché questo richiede molto tempo e risorse computazionali, il rendering dei siti web basati su JavaScript viene differito fino a quando Googlebot non dispone delle risorse disponibili per elaborare tali contenuti.
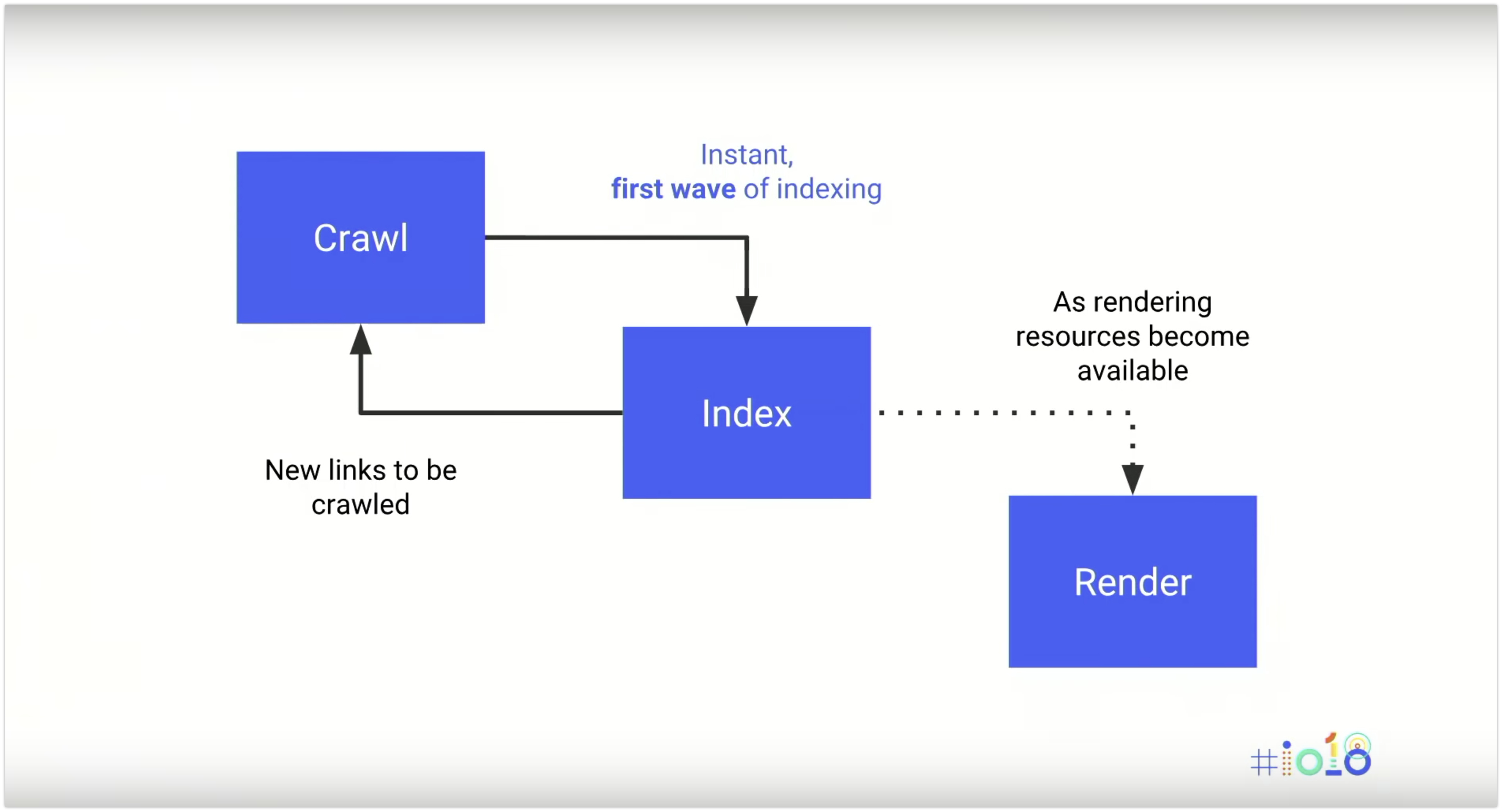
Questo significa che Googlebot esegue effettivamente due ondate di indicizzazione tra i contenuti, ed è possibile che alcuni dettagli vadano persi. È importante che i SEO che lavorano su siti basati su JavaScript si assicurino che alcuni elementi importanti - come meta dati, codici di stato HTTP o tag canonici - vengano renderizzati (o siano disponibili già) prima della prima ondata di indicizzazione - per evitare che vadano perduti. Ad esempio, la seconda ondata di indicizzazione non controlla affatto la presenza del canonical tag (!!!).
Diversi tipi di rendering
Vediamo i diversi tipi di rendering disponibili:
-
Rendering lato client - JavaScript è eseguito sul client, che sia il browser o un motore di ricerca;
-
Rendering lato server - Il server elabora il codice JavaScript e serve principalmente HTML statico ai motori di ricerca. Questo apporta vantaggi di velocità, specialmente per le connessioni più lente e per i dispositivi di fascia bassa;
-
Rendering ibrido - L'HTML pre-renderizzato viene inviato al client in modo da ottenere gli stessi vantaggi di velocità del rendering lato server. Tuttavia, con l'interazione o dopo il caricamento della pagina,il server aggiunge ulteriore JavaScript. In questo scenario, Google recupera il contenuto HTML pre-renderizzato.
Google considera la soluzione del rendering ibrido quella da raccomandare a lungo termine. Tuttavia, nella pratica la sua implementazione è ancora un po’ complicata, anche se alcuni framework JavaScript hanno eleborato delle soluzioni in tal senso (vedi Angular Universal).
Un’altra opzione presentata da Google per ovviare al problema dell'indicizzazione differita, è quella del rendering dinamico, che prevede:
- l’invio di contenuto renderizzato lato client agli utenti;
- l'invio di contenuti renderizzati completamente lato server ai motori di ricerca e ad altri crawler che ne hanno bisogno - tramite l’identificazione di questi tramite user-agent.
Questo è un vero e proprio cambiamento della policy di Google: all’interno della guida per la Search Console, si afferma infatti:
"se il tuo sito utilizza tecnologie a cui i motori di ricerca accedono con difficoltà, come JavaScript, immagini o file Flash, leggi i nostri consigli per rendere tali contenuti accessibili ai motori di ricerca e agli utenti senza ricorrere al cloaking.”
E in questo articolo del Webmaster Central Blog :
“In generale, i siti web non dovrebbero ricorrere al pre-rendering solo per Google”.
Come implementare il rendering dinamico
Google raccomanda di aggiungere un nuovo strumento o uno step nell'infrastruttura del server che agisca come un renderer dinamico.
Questo leggerà il contenuto renderizzato lato client e invierà una versione pre-renderizzata ai crawler dei motori di ricerca. Ci sono due opzioni che ti aiutano a ottenere questo risultato:
-
Il primo è Puppeteer, che è una libreria Node.js, che include una versione headless di Google Chrome.
-
Un'altra opzione è Rendertron, che puoi eseguire come software, come un servizio che esegue il rendering e memorizza nella cache i tuoi contenuti.
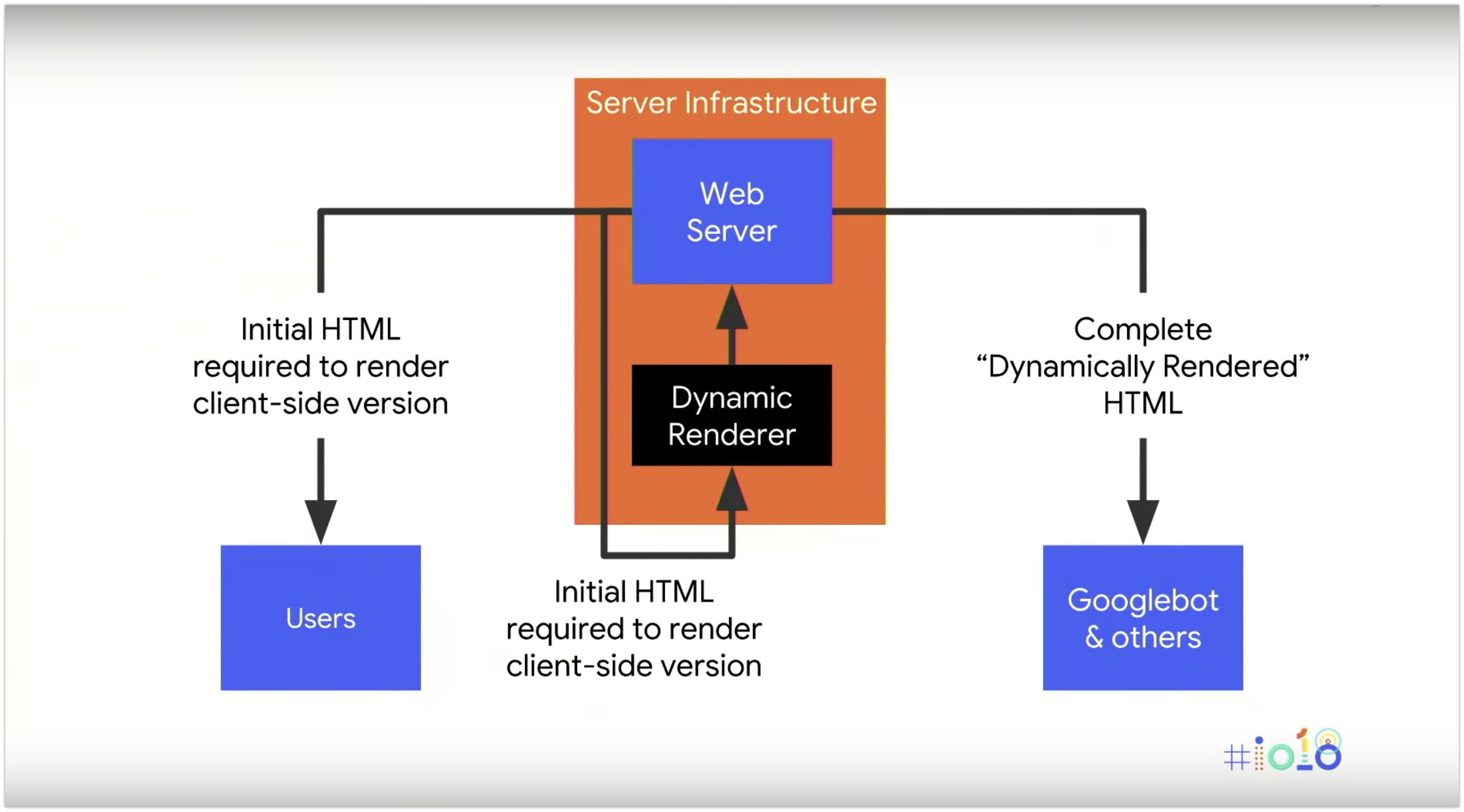
L’infrastruttura del server assomiglierà all’immagine qui sopra: le richieste di Google vengono inviate al tuo server normale, e - ad esempio tramite un proxy inverso - vengono inviati al renderer dinamico. Questo richiede e restituisce l’intera pagina finale e la invia ai motori di ricerca.
Quindi, senza la necessità di implementare o mantenere alcun nuovo codice, questa configurazione potrebbe permettere a un sito web progettato solo per il rendering lato client di eseguire il rendering dinamico del contenuto per Googlebot e altri client.
Con questa soluzione possiamo essere certi che il contenuto importante delle nostre pagine Web sia disponibile per Googlebot quando esegue la sua prima ondata di indicizzazione.
Riconoscere Googlebot tramite l'user-agent
Il modo più semplice per riconoscere Googlebot è identificarlo tramite la stringa dell’user-agent. Puoi fare lo stesso per gli altri servizi a cui vuoi offrire contenuti pre-renderizzati.
Puoi anche eseguire una ricerca DNS inversa se vuoi essere sicuro che lo stai servendo solo ai client corretti. Una cosa da tenere a mente è che, se offri contenuti adattati per utenti smartphone rispetto agli utenti desktop o reindirizzi gli utenti a URL diversi a seconda del dispositivo che usano, devi assicurarti che il rendering dinamico serva il giusto contenuto a seconda del dispositivo.
In altre parole, i crawler dei motori di ricerca mobile, quando visitano le tue pagine web, dovrebbero vedere la versione mobile della pagina. E gli altri dovrebbero vedere la versione desktop.
Ma se utilizzi un design responsive, significa che utilizzi lo stesso codice HTML. In questo caso non ti devi preoccupare, perché L'HTML è esattamente lo stesso.
Ciò che non è immediatamente chiaro dagli user-agent è che Googlebot sta attualmente utilizzando un browser un po' datato per il rendering delle pagine, ovvero Chrome 41, che è stato rilasciato nel 2015 (ecco lo SPOILER di prima :D)

L'implicazione più evidente per gli sviluppatori è che le nuove versioni JavaScript e le “coding conventions”, ad esempio le arrow functions, non sono supportate da Googlebot. Questo vuol dire anche che qualsiasi API che sia stata aggiunta dopo Chrome 41, al momento non è supportata. Puoi tuttavia controllare cos’è supportato e cosa no su un sito come CanIuse.com.
Rendering dinamico: quando utilizzarlo?
Il primo motivo per cui adottare il rendering dinamico, è se il tuo sito è grande e in rapida evoluzione. Ad esempio, se si dispone di un sito Web di news, avrai un sacco di nuovi contenuti che continuano a uscire regolarmente e questo richiede una rapida indicizzazione. Il rendering viene differito dall'indicizzazione, quindi, se disponi di un sito web ampio e dinamico, il nuovo contenuto potrebbe impiegare un po' di tempo per essere indicizzato.
In secondo luogo, se ci si basa sulla moderna funzionalità JavaScript. Ad esempio, se si dispone di librerie che non possono essere trasformate in ES5, il rendering dinamico può esserti d'aiuto. Detto questo, Google continua a raccomandare l'uso di tecniche di graceful degradation, in modo che anche i client più vecchi possano accedere ai tuoi contenuti.
La Graceful degradation è una metodologia di sviluppo che prevede di fornire le funzionalità di un sito web in modo che degradino in maniera graduale ad un livello inferiore di user experience sui browser più vecchi.
E infine, c'è un terzo motivo: se il tuo sito si basa sulla condivisione attraverso i social media o attraverso le applicazioni di chat. Se questi servizi richiedono l'accesso ai contenuti della tua pagina, il rendering dinamico può aiutarti anche lì.
Tool di diagnostica
Google consiglia di testare il corretto funzionamento del rendering in modo incrementale. In primo luogo, controllando la risposta HTTP non elaborata, poi controllando la versione renderizzata, su dispositivo mobile o su dispositivo mobile e desktop se servi contenuti diversi a seconda del device.
Un modo per controllare la risposta HTTP non elaborata è utilizzare la Search Console di Google e lo strumento Visualizza come Google, che mostrerà la risposta HTTP ricevuta da Googlebot, incluso il codice di risposta e l'HTML che è stato fornito prima del rendering.
Questo è un ottimo modo per controllare ciò che sta accadendo sul tuo server, specialmente se stai utilizzando il rendering dinamico per offrire contenuti diversi a Googlebot. Una volta controllata la risposta non elaborata, Google consiglia di controllare come viene effettivamente visualizzata la pagina.
Qui lo strumento da utilizzare è il test per dispositivi mobili (è opportuno iniziare a concentrarsi sulla versione mobile quando si esegue il test del rendering, perché Google incentrerà l’indicizzazione principalmente sulla versione mobile di una pagina - meglio conosciuto come Mobile First Indexing)
Google consiglia di testare alcune pagine per ogni tipo all'interno del tuo sito web. Ad esempio, se disponi di un sito di e-commerce, controlla la homepage, alcune categorie e alcune pagine prodotto. Non è necessario controllare tutte le pagine del sito Web, perché spesso i template saranno molto simili.
Se le tue pagine vengono visualizzate correttamente, allora è molto probabile che Googlebot possa effettuare il rendering delle tue pagine. Tuttavia, uno svantaggio di questo tool è che puoi vedere solo lo screenshot. Qui non vedi ancora l'HTML renderizzato.
Google ha presentato quindi un nuova funzionalità in esclusiva per I / O,per visualizzare l'HTML dopo il rendering, sempre all’interno del test per dispositivi mobili.

Questa funzione ti mostra ciò che è stato creato dopo il rendering con il Googlebot mobile crawler. Comprende anche il markup per i link, per le immagini, per i dati strutturati, tutti gli elementi invisibili che potrebbero essere sulla pagina dopo il rendering.
Ma cosa fare se la pagina non viene visualizzata correttamente?
Google ha introdotto un modo per ottenere informazioni complete sui problemi di caricamento di una pagina. In questa sezione del test per dispositivi mobili (nell'immagine sotto), puoi visualizzare tutte le risorse bloccate a cui Googlebot non può accedere. Spesso non c’è bisogno che tutte le risorse siano sottoposte a scansione: ad esempio, se hai pixel di tracciamento su una pagina, Googlebot non ha realmente bisogno di effettuare il rendering su di essi. Ma se si utilizza un'API per inserire il contenuto da qualche altra parte e l'endpoint dell'API è bloccato dal robots.txt, allora non sarà possibile per Google inserire tali contenuti.
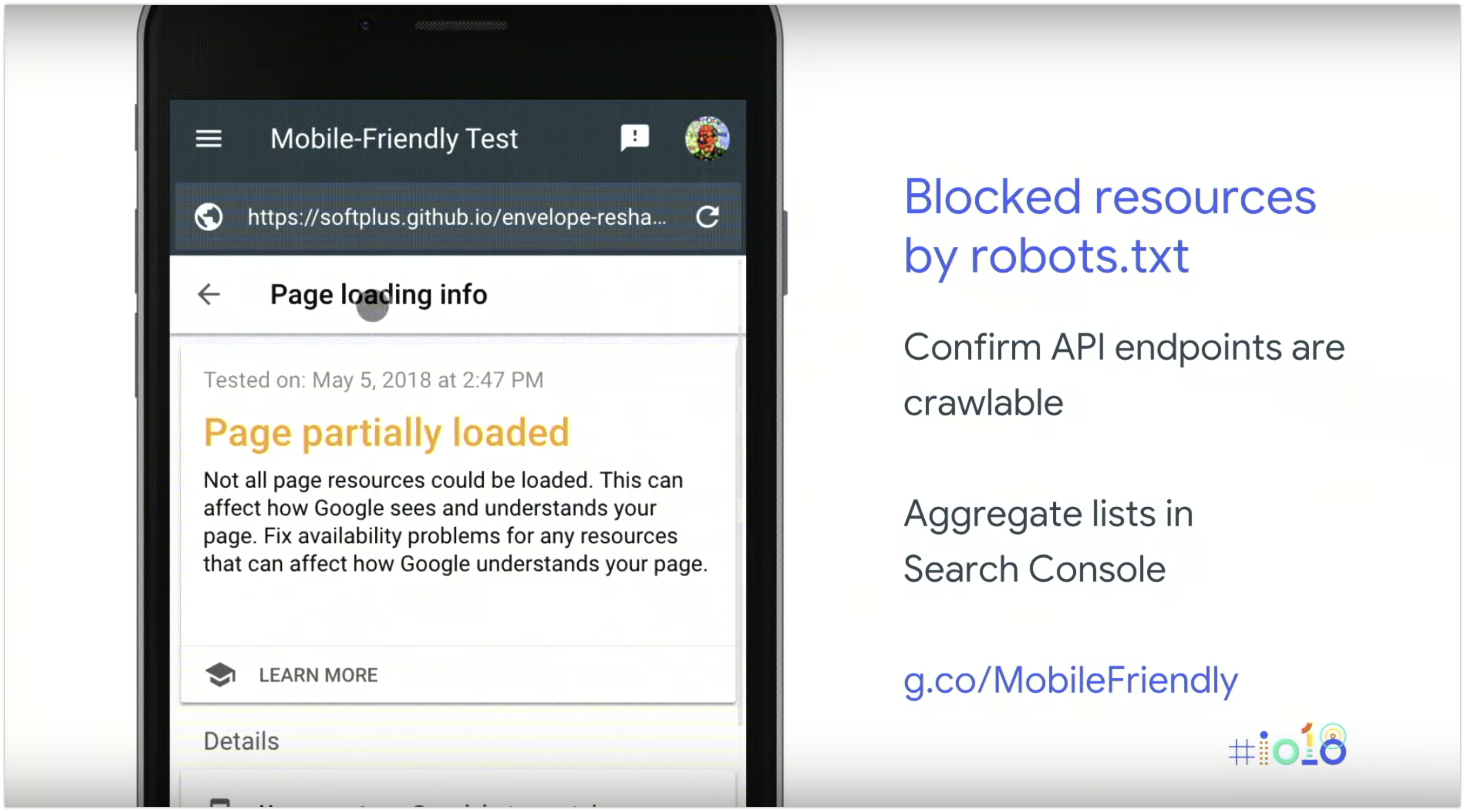
Un elenco di tutti questi problemi è disponibile anche nella Search Console (nell’elenco di risorse bloccate nel tool Visualizza come Google).
Un’altra novità in esclusiva per Google I/O - una delle funzionalità più richieste da chi realizza siti basati su JavaScript - è il log della console ogniqualvolta Googlebot tenta di eseguire il rendering.
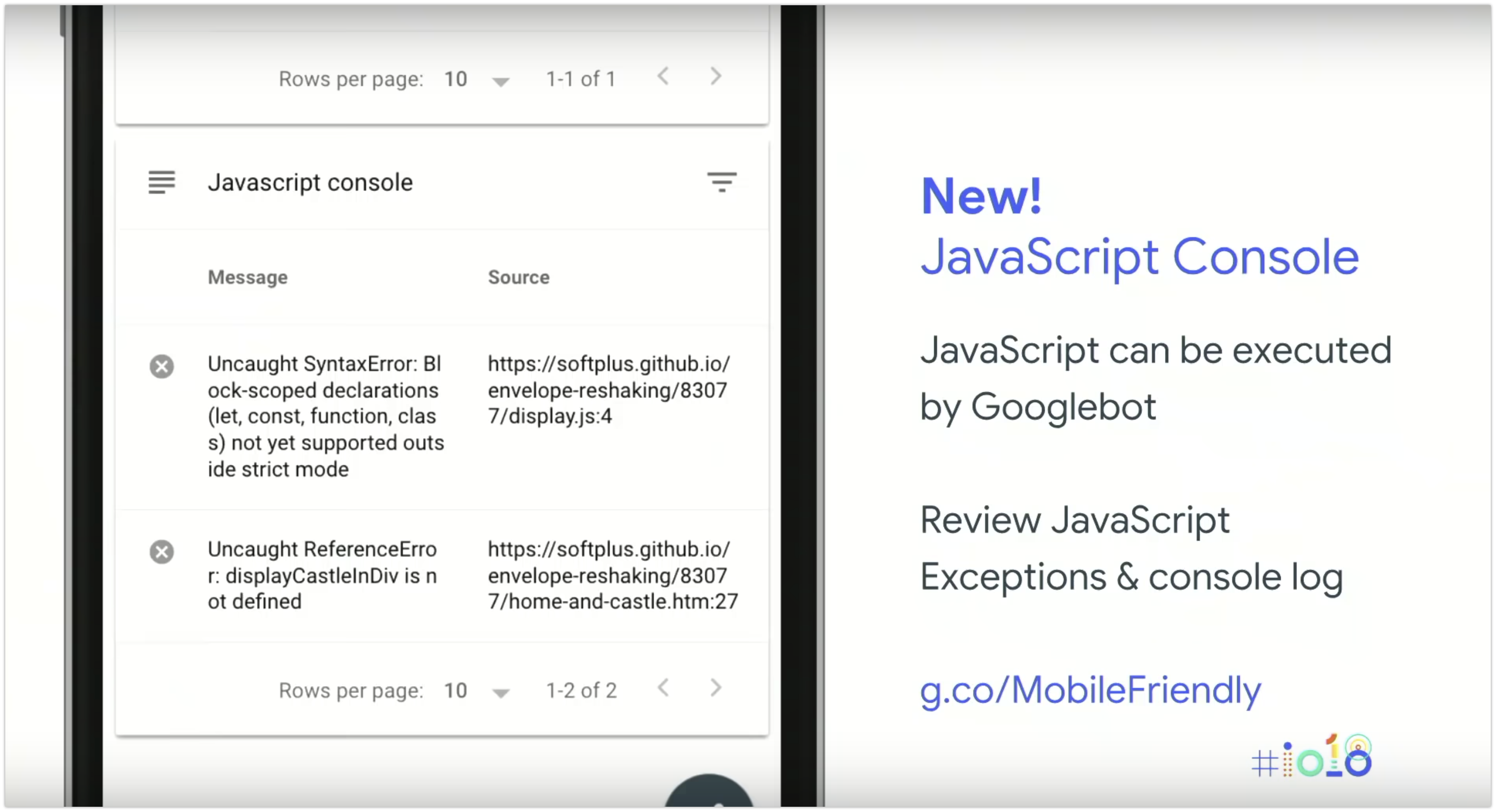
Questo ti permette di verificare ogni tipo di problema legato a JavaScript.
Infine, puoi eseguire tutte queste diagnostiche per la versione desktop utilizzando il Rich Result test.
Funzionalità in Javascript: alcune considerazioni
Il Lazy Loading
“Con Lazy Loading (caricamento pigro) si intende un download di script on demand, ovvero solamente quando essi sono effettivamente necessari per il prosieguo dell’applicazione.” - HTML.it
A seconda di come viene implementato il lazy loading, Googlebot può essere in grado o meno di “innescarlo” e quindi, può essere in grado o meno di utilizzare queste immagini per l'indicizzazione.
Ad esempio, se le immagini si trovano above the fold, e se il lazy loading esegue automaticamente le immagini, Googlebot probabilmente sarà in grado di vederle. Ma se vuoi essere sicuro che Googlebot sia in grado di acquisire immagini caricate tramite lazy loading, un modo per farlo è quello di utilizzare un tag noscript.

Puoi aggiungere un tag noscript a un normale elemento immagine e Google sarà in grado di selezionare tale elemento per la Ricerca Immagini.Un altro approccio consiste nell'utilizzare dati strutturati su una pagina (esempio sotto). Google non indicizza le immagini a cui si fa riferimento solo tramite CSS.

Click-to-load patterns
Oltre alle immagini caricate tramite lazy loading, ci sono altri tipi di contenuti che richiedono qualche tipo di interazione per essere caricati. Ad esempio è il caso delle tab che caricano il contenuto solo dopo aver fatto clic su di esse, o quando si utilizza la funzionalità “infinite scrolling”. Googlebot generalmente non interagisce con la pagina, e non sarebbe in grado quindi di vederli.
Ci sono due modi in cui puoi risolvere questo problema:
- puoi pre-caricare il contenuto e utilizzare semplicemente il CSS per attivare o disattivarne la visibilità.In questo modo Googlebot può vedere quel contenuto dalla versione pre-caricata.
- In alternativa, puoi semplicemente utilizzare URL separati e indirizzare gli utenti e Googlebot in modo individuale.
Timeouts
Googlebot ha molte pagine da sottoporre a scansione - questo vuol dire che le pagine lente e inefficienti verranno sottoposte a scansione in modo non consistente. John Müller consiglia di realizzare pagine Web performanti ed efficienti, e in particolare, di:
- limitare il numero di risorse embeddate;
- evitare ritardi artificiali come i “timed interstitials”.
"No Browser State"
Googlebot vuole vedere la pagina come la vedrebbe un nuovo utente. Quindi esegue la scansione e il rendering delle pagine in modo “stateless” (= ogni richiesta è indipendente da quelle precedenti). Questo significa che qualsiasi API che tenti di archiviare qualcosa localmente non è supportata.
Pertanto, se utilizzi una di queste tecnologie, Google consiglia di utilizzare tecniche di “graceful degrading” per consentire a chiunque di visualizzare le tue pagine, anche quando queste API non sono supportate.
SEO & JavaScript in 4 passaggi
Per ricapitolare:
- verifica la corretta implementazione delle best-practices di cui abbiamo parlato. In particolare per quanto riguarda le immagini caricate tramite lazy loading, ormai molto diffuse.
- testa un set delle tue pagine con il test di per dispositivi mobile e usa anche le altre funzionalità. Ricorda che non è necessario testare tutte le tue pagine.
- se le tue pagine o il tuo sito web sono di grandi dimensioni o i tuoi contenuti cambiano frequentemente, o non è possibile sistemare il rendering in modo ragionevole, allora dovresti prendere in considerazione l'utilizzo di tecniche di rendering dinamico per offrire a Googlebot e ad altri crawler una versione pre-renderizzata della pagina.
- se decidi di utilizzare il rendering dinamico, assicurati di monitorarne i risultati.
Infine, una cosa da tenere a mente: l'indicizzazione e il posizionamento non sono la stessa cosa. Ma in generale, le pagine devono essere indicizzate prima che il loro contenuto possa apparire nella Ricerca di Google.
I piani futuri di Google per la ricerca
Google vuole che i risultati di ricerca riflettano il Web indipendentemente dal tipo di sito Web utilizzato. Quindi la loro visione di lungo termine è che gli sviluppatori non debbano preoccuparsi tanto delle tecnologie utilizzate.
Uno dei cambiamenti che vogliono attuare è far sì che l'attività di rendering sia più vicina alla scansione e all'indicizzazione (per evitare due ondate di indicizzazione).
Un altro cambiamento che vogliono apportare è far sì che Googlebot utilizzi una versione più moderna di Chrome in futuro (John Müller afferma che dovremo aspettare probabilmente la fine dell'anno).
E questo è tutto!
Risorse utili:
developers.google.com/search/docs/guides/rendering
https://webmasters.googleblog.com/2018/05/helping-webmasters-and-content.html
Qual è la tua opinione sul tema SEO & JavaScript?
Aspetto i tuoi commenti.
[ create-campaign bg_images="https://static.semrush.com/blog/uploads/media/a4/4f/a44f7a6614c3ee4fc6b627878d5be0ee/website-performance-research-semrush-2018-back-banner.png" bg_button="-success" header="Verifica le prestazioni del tuo sito web" text="con Site Audit di SEMrush"]