Il tuo Site Audit non funziona correttamente?
Ci sono diversi motivi per cui al crawler di Site Audit viene impedito di analizzare le pagine, in base alla configurazione e alla struttura del tuo sito web. Tra questi:
- Il file Robots.txt blocca il crawler
- L'ambito del crawling esclude alcune aree del sito
- Il sito non è direttamente online a causa dell'hosting condiviso
- Dimensioni della landing page superiori a 2Mb
- Le pagine si trovano dietro un gateway/un'area del sito riservata
- Il crawler viene bloccato dal tag noindex
- Il dominio non può essere risolto dal DNS: il dominio inserito nella configurazione è offline
- Contenuti del sito web costruiti su JavaScript. Anche se Site Audit è in grado di eseguire il rendering del codice JS, questo può comunque essere la causa di alcuni problemi
Step per la risoluzione dei problemi
Segui questi step di risoluzione dei problemi per vedere se riesci a correggere qualcosa da solo prima di rivolgerti al nostro team di assistenza.
Un file Robots.txt fornisce istruzioni ai bot su come scansionare (o non scansionare) le pagine di un sito web. Puoi consentire e vietare a bot come Googlebot o Semrushbot di effettuare il crawling di tutto il tuo sito o di aree specifiche del sito utilizzando comandi come Allow, Disallow e Crawl Delay.
Se il tuo robots.txt impedisce al nostro bot di eseguire il crawling, il nostro strumento Site Audit non sarà in grado di controllare il tuo sito.
Puoi controllare il tuo Robots.txt alla ricerca di eventuali comandi Disallow che impediscano a crawler come il nostro di accedere al tuo sito web.
Per consentire al bot Semrush Site Audit (SiteAuditBot) di effettuare il crawling del tuo sito, aggiungi quanto segue al tuo file robots.txt:
User-agent: SiteAuditBot
Disallow:
(lascia uno spazio vuoto dopo "Disallow:")
Ecco un esempio di come può apparire un file robots.txt:

Nota i vari comandi in base allo user agent (crawler) a cui il file si rivolge.
Questi file sono pubblici e per essere trovati devono essere nel livello superiore di un sito. Per trovare il file robots.txt di un sito web, inserisci nel tuo browser il dominio principale del sito seguito da /robots.txt. Ad esempio, il file robots.txt di Semrush.com si trova all'indirizzo https://semrush.com/robots.txt.
Tra i termini che potresti vedere in un file robots.txt ci sono:
- User-Agent = il web crawler a cui stai dando istruzioni.
- Es: SiteAuditBot, Googlebot
- Allow = un comando (solo per Googlebot) che indica al bot che può effettuare il crawling di una pagina o di un'area specifica di un sito anche se la pagina o la cartella madre sono vietate.
- Disallow = un comando che indica al bot di non effettuare il crawling di uno specifico URL o sottocartella di un sito.
- Es: Disallow: /admin/
- Crawl Delay = un comando che indica ai bot quanti secondi aspettare prima di caricare e analizzare un'altra pagina.
- Sitemap = indica dove si trova il file sitemap.xml per un determinato URL.
- / = utilizza il simbolo "/" dopo un comando disallow per indicare al bot di non effettuare il crawling dell'intero sito
- * = un simbolo jolly che rappresenta qualsiasi stringa di caratteri possibili in un URL, utilizzato per indicare un'area di un sito o tutti gli user agent.
- Es: Disallow: /blog/* indicherebbe tutti gli URL della sottocartella blog di un sito
- Es: User Agent: * indicherebbe istruzioni per tutti i bot
Per saperne di più sulle specifiche del file Robots.txt consulta Google o il blog di Semrush.
Se vedi il seguente codice nella pagina principale di un sito web, ci dice che non ci è permesso indicizzare/seguire i link presenti e che il nostro accesso è bloccato.
meta name="robots" content="noindex, nofollow"
Oppure, una pagina contenente almeno uno dei seguenti elementi: "noindex", "nofollow", "none", porterà all'errore di scansione.
Per consentire al nostro bot di eseguire la scansione di una pagina di questo tipo, rimuovi questi tag "noindex" dal codice della tua pagina. Per maggiori informazioni sul tag noindex, consulta questo articolo del Supporto Google.
Per inserire il bot nella whitelist, contatta il tuo webmaster o il tuo provider di hosting e chiedigli di inserire SiteAuditBot nella whitelist.
Gli indirizzi IP del bot sono: 85.208.98.128/25 (una sottorete utilizzata solo da Site Audit)
Il bot utilizza le porte standard 80 HTTP e 443 HTTPS per connettersi.
Se utilizzi dei plugin (Wordpress, ad esempio) o dei CDN (content delivery network) per gestire il tuo sito, dovrai inserire l'IP del bot nella whitelist anche di questi.
Per la whitelist su Wordpress, contatta il supporto di Wordpress.
I CDN più comuni che bloccano il nostro crawler includono:
- Cloudflare - leggi come inserire nella whitelist qui
- Imperva - leggi come inserire nella whitelist qui
- ModSecurity - leggi come inserire nella whitelist qui
- Sucuri - leggi come inserire nella whitelist qui
Nota bene: se disponi di un hosting condiviso, è possibile che il tuo provider non ti permetta di inserire nella whitelist i bot o di modificare il file Robots.txt.
Fornitori di hosting
Di seguito ti elenchiamo alcuni dei provider di hosting più famosi del web e le modalità per inserire un bot nella whitelist di ciascuno di essi o per richiedere assistenza al loro team di supporto:
- Siteground - istruzioni per la whitelist
- 1&1 IONOS - istruzioni per la whitelist
- Bluehost* - istruzioni per la whitelist
- Hostgator* - istruzioni per la whitelist
- Hostinger - istruzioni per la whitelist
- GoDaddy - istruzioni per la whitelist
- GreenGeeks - istruzioni per la whitelist
- Big Commerce - È necessario contattare il supporto
- Liquid Web - È necessario contattare il supporto
- iPage - È necessario contattare il supporto
- InMotion - È necessario contattare il supporto
- Glowhost - È necessario contattare il supporto
- Hosting – È necessario contattare il supporto
- DreamHost - È necessario contattare il supporto
* Nota bene: queste istruzioni sono valide per HostGator e Bluehost se hai un sito web su VPS o un Hosting dedicato.
Se le dimensioni della landing page o le dimensioni totali dei file JavaScript/CSS superano i 2 Mb, i nostri crawler non saranno in grado di elaborarli a causa delle limitazioni tecniche dello strumento.
Per saperne di più su cosa potrebbe causare l'aumento delle dimensioni e su come risolvere il problema, puoi consultare questo articolo del nostro blog.
Per vedere quanto è stato utilizzato il tuo budget di crawling attuale, vai su Profilo - Dati sull'abbonamento e cerca "Pagine da analizzare" sotto "Toolkit SEO".
A seconda del tuo livello di abbonamento, hai un numero limitato di pagine da analizzare in un mese (budget di crawling mensile). Se superi il numero di pagine consentito dal tuo abbonamento, dovrai acquistare ulteriori limiti o aspettare il mese successivo, quando i tuoi limiti verranno ripristinati.
Inoltre, se ricevi il messaggio di errore "Hai raggiunto il limite di campagne condotte in contemporanea" durante la configurazione, significa che hai raggiunto il numero massimo di audit che ti è consentito eseguire contemporaneamente per il tuo piano di abbonamento.
Ogni livello di abbonamento prevede limiti diversi:
- Account gratuito: 1 sito alla volta
- Toolkit SEO Pro: Fino a 2 audit di siti contemporaneamente
- Toolkit SEO Guru: Fino a 2 audit di siti contemporaneamente
- Toolkit SEO Business: Fino a 5 audit di siti contemporaneamente
Se il dominio non può essere risolto dal DNS, probabilmente significa che il dominio inserito durante la configurazione è offline. Di solito gli utenti hanno questo problema quando inseriscono un dominio principale (example.com), senza rendersi conto che la versione del dominio principale del loro sito non esiste e che è necessario inserire la versione WWW (www.example.com).
Per evitare questo problema, il proprietario del sito web potrebbe aggiungere un redirect dal sito non protetto "example.com" al sito protetto "www.example.com" che esiste sul server. Questo problema potrebbe verificarsi anche al contrario, se il dominio root di qualcuno è protetto, ma la sua versione WWW no. In questo caso, dovrai semplicemente reindirizzare la versione WWW al dominio principale.
Se la tua homepage ha dei link al resto del sito nascosti in elementi JavaScript, devi abilitare il JS-rendering, in modo che possiamo leggerli e fare il crawling di quelle pagine. Questa funzionalità è disponibile per i livelli Guru e Business dell'abbonamento al Toolkit SEO.
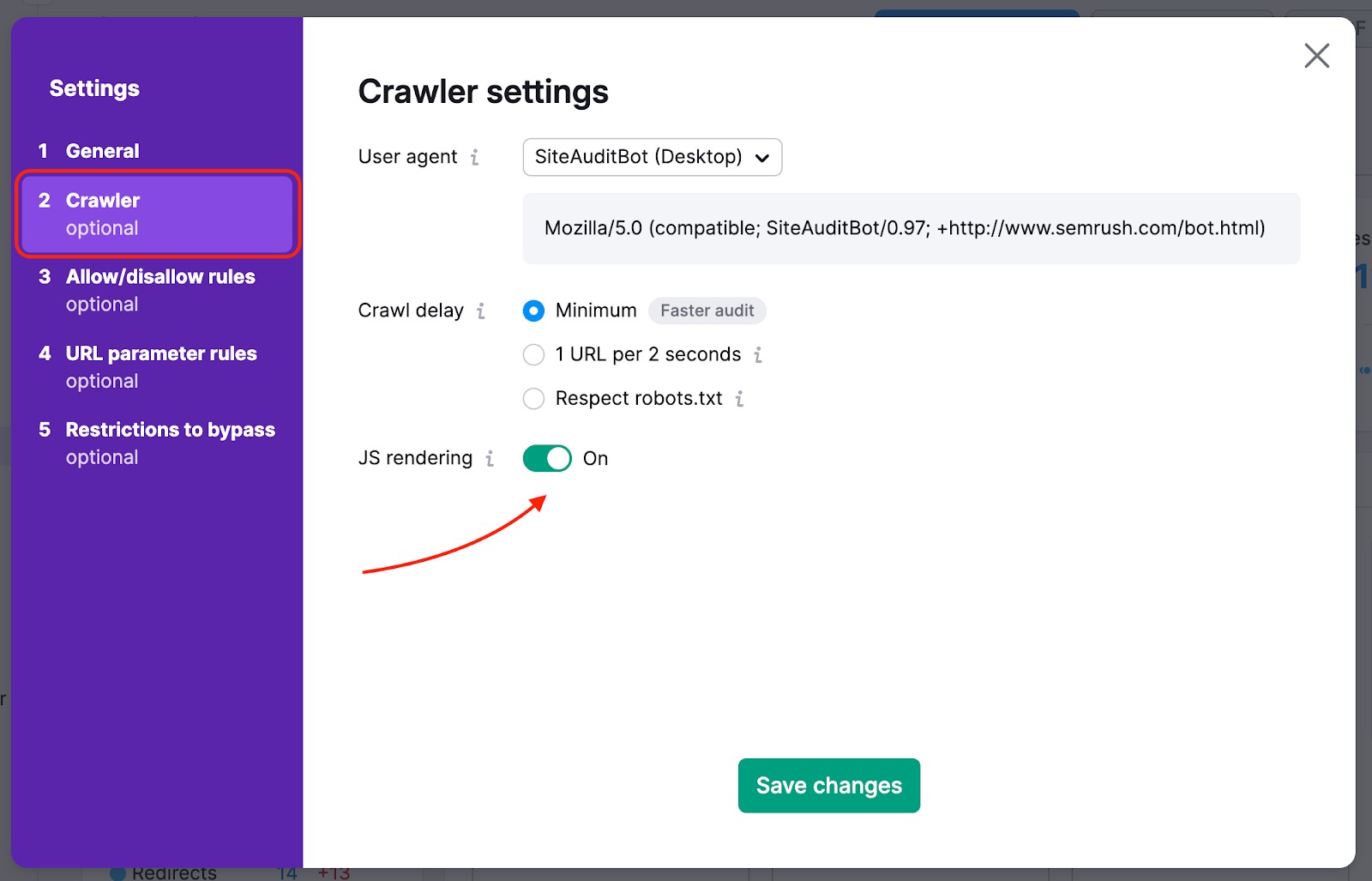
Per non perdere le pagine più importanti del tuo sito web con il nostro crawl, puoi cambiare la fonte della scansione da sito web a sitemap: in questo modo, i crawler non perderanno le pagine più difficili da trovare naturalmente sul sito web durante l'audit.
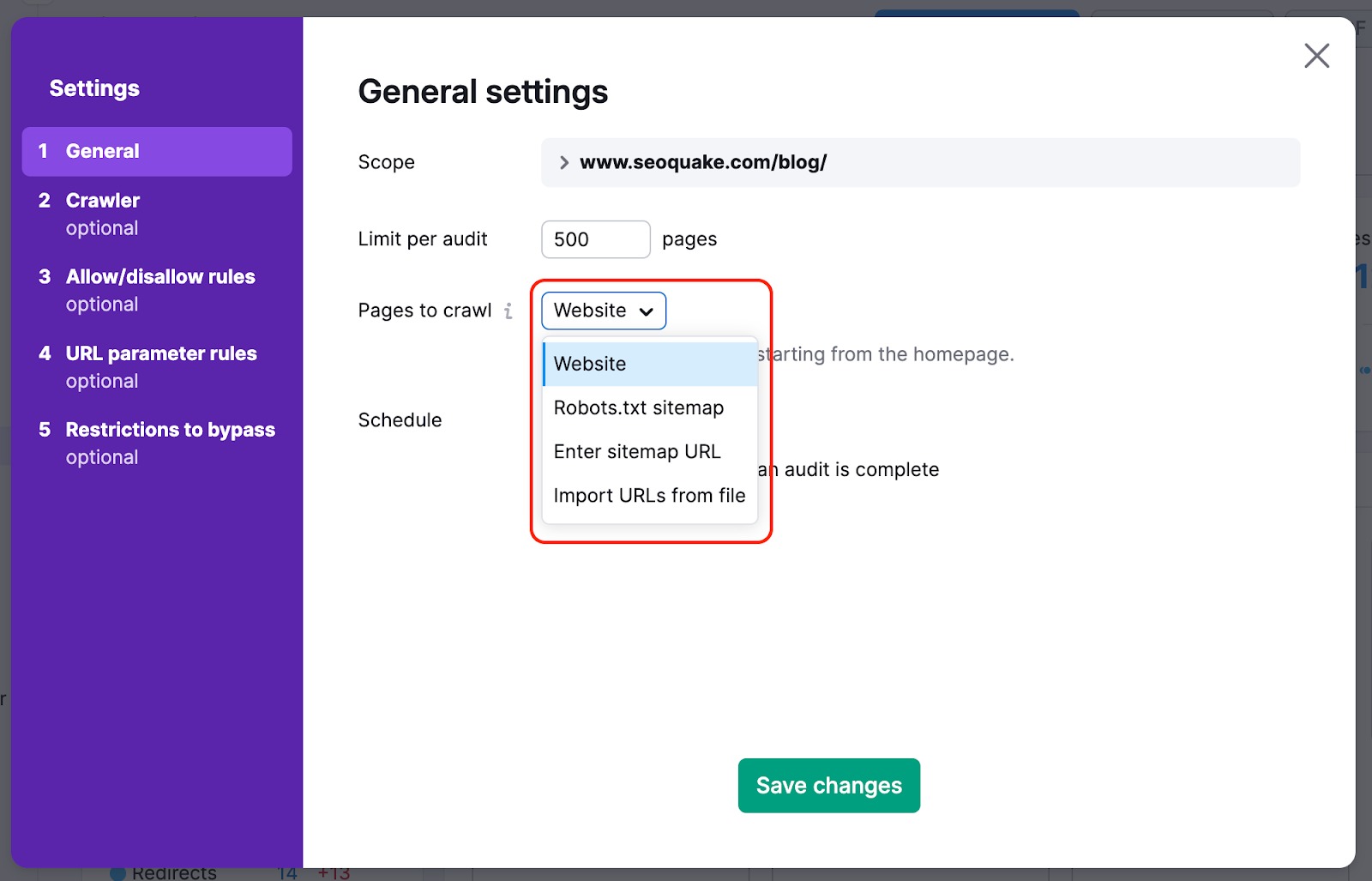
Possiamo anche eseguire il crawling dell'HTML di una pagina con alcuni elementi JS ed esaminare i parametri dei tuoi file JS e CSS con i nostri controlli Performance.
Il tuo sito web potrebbe bloccare SemrushBot nel tuo file robots.txt. Puoi cambiare l'User Agent da SemrushBot a GoogleBot e il tuo sito web probabilmente permetterà all'User Agent di Google di effettuare il crawling. Per effettuare questa modifica, trova l'ingranaggio delle impostazioni nel tuo Progetto e seleziona User Agent.
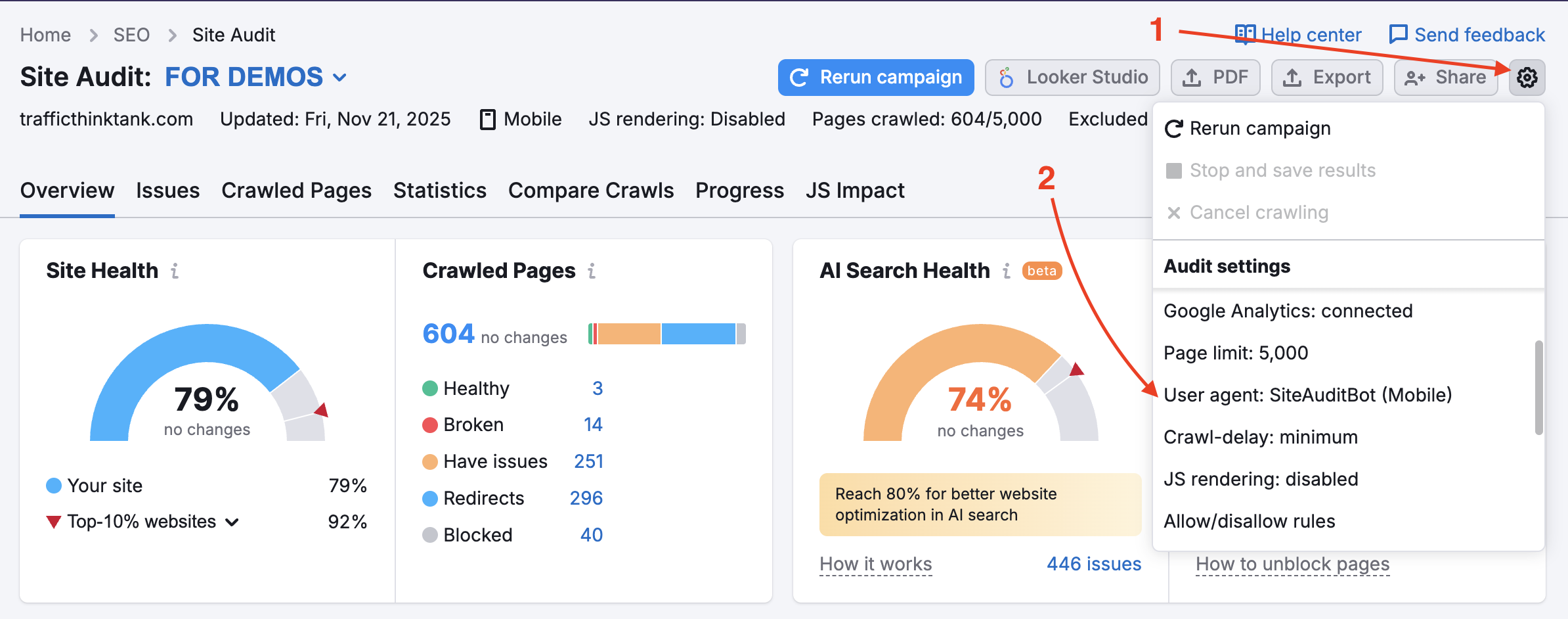
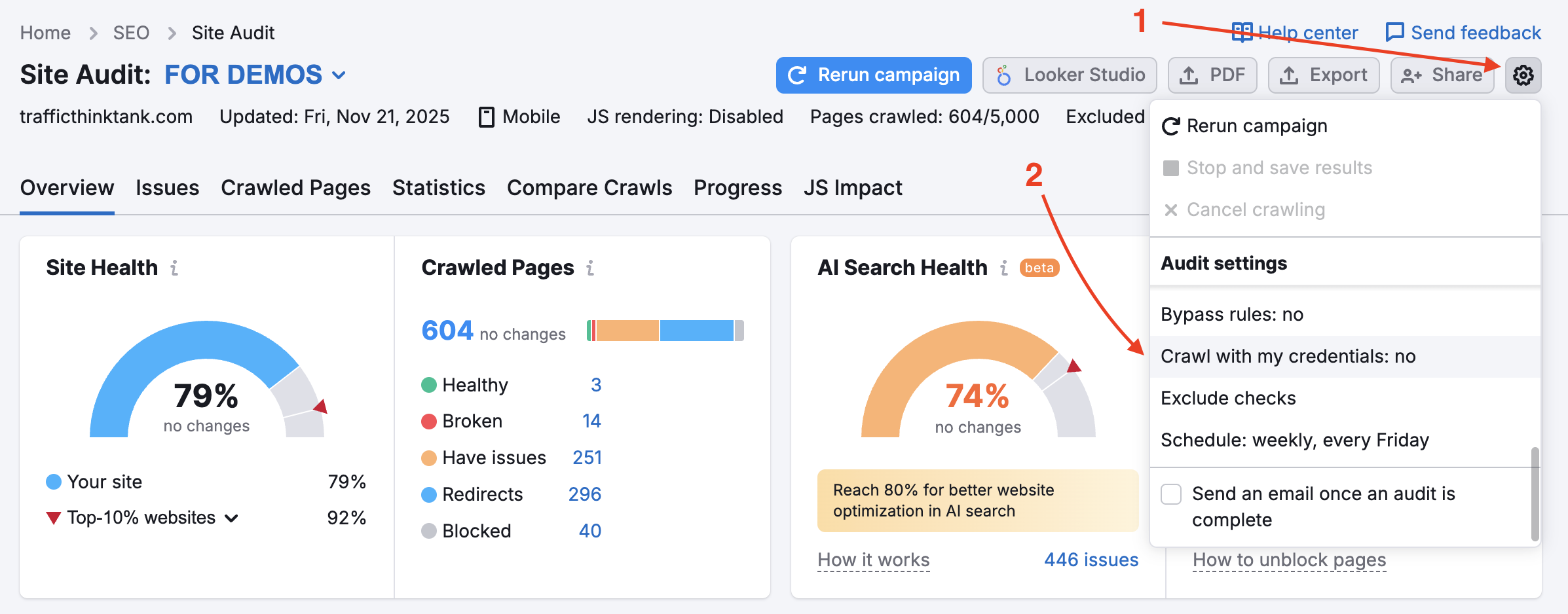
Quando questa opzione è attivata, il crawler ignorerà le regole di esclusione del file robots.txt; di conseguenza, saranno incluse nelle scansioni pagine e risorse interne che normalmente verrebbero bloccate. Tieni presente che per utilizzarla è necessario verificare la proprietà del sito.
Questa opzione è utile per i siti che sono in fase di manutenzione. È utile anche quando il proprietario del sito non vuole modificare il file robots.txt.
Per controllare le aree private del tuo sito web che sono protette da password, inserisci le tue credenziali nell'opzione "Crawling con le tue credenziali" nell'ingranaggio delle impostazioni.
Questa procedura è particolarmente raccomandata per i siti ancora in fase di sviluppo o che sono privati e protetti da password.
Alcuni siti web e piattaforme di hosting, come Shopify, potrebbero bloccare i bot sconosciuti per motivi di sicurezza o di prestazioni. Se il tuo audit su queste piattaforme non riesce, l'aggiunta di una firma Web Bot Auth consente al crawler di Semrush di identificarsi e di dimostrare di essere autorizzato ad accedere al tuo sito web.

Se non hai fornito una firma durante la configurazione iniziale e il tuo sito è bloccato, Semrush rileverà la restrizione e ti chiederà di risolverla direttamente dall'interfaccia dello strumento.

"Le impostazioni del crawler sono cambiate rispetto all'audit precedente. Questo potrebbe influenzare i risultati dell'audit in corso e il numero di problemi rilevati."
Questa notifica appare in Site Audit dopo aver aggiornato le impostazioni e aver rieseguito l'audit. Non si tratta della segnalazione di un problema, ma piuttosto di una nota che riporta un possibile motivo della variazione dei risultati dell'analisi.
Dai un'occhiata al nostro articolo sul blog, Problemi comuni relativi alla SEO e come risolverli.