Quando crei la tua prima cartella in Semrush, Site Audit viene configurato e avviato automaticamente per il dominio che hai inserito. È possibile visualizzare i risultati accedendo allo strumento Site Audit dal menù a sinistra o dalla home page una volta completata la scansione iniziale.
Per tutte le cartelle successive che creerai, dovrai configurare Site Audit manualmente. Per farlo, crea una nuova cartella da Site Audit e segui le istruzioni per configurare e lanciare la tua campagna di audit.
Se hai problemi a far funzionare il tuo Site Audit, consulta la guida Risoluzione dei problemi di Site Audit.
Impostazioni generali
Verrà visualizzata la prima parte della configurazione guidata, intitolata "Impostazioni generali". Da qui puoi scegliere o di cliccare su "Avvia audit", che eseguirà immediatamente un audit del tuo sito con le nostre impostazioni predefinite, o di procedere alla personalizzazione delle impostazioni dell'audit a tuo piacimento. Ma non preoccuparti, puoi sempre modificare le impostazioni e eseguire nuovamente la scansione di un'area più specifica del tuo sito dopo la configurazione iniziale.
Ambito crawling
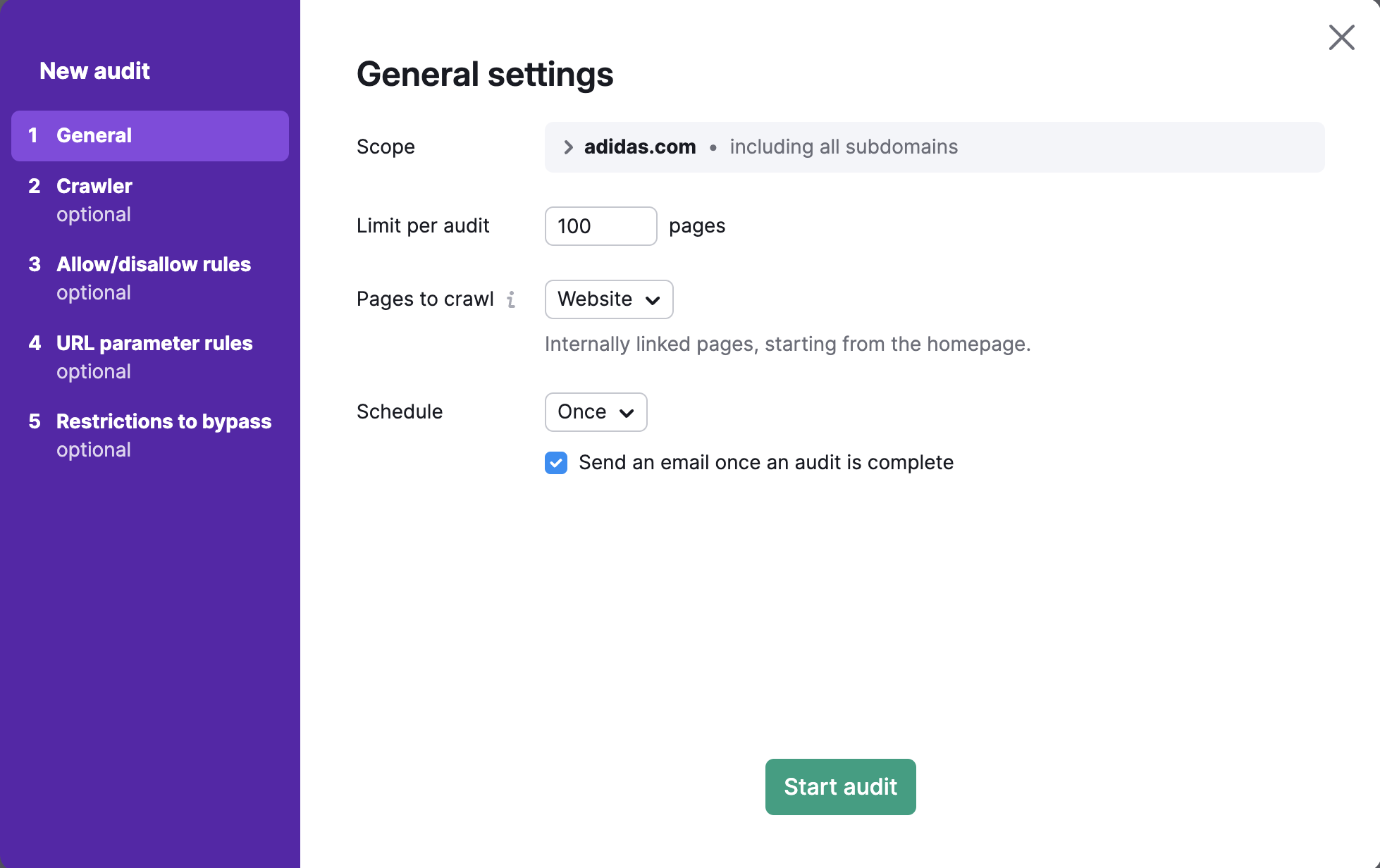
Per eseguire la scansione di un dominio, sottodominio o sottocartella specifici, puoi inserirli nel campo “Ambito”. Se inserisci un dominio in questo campo, ti verrà data l'opzione di eseguire una scansione di tutti i sottodomini del tuo dominio con una casella di controllo.
Per impostazione predefinita lo strumento verifica il dominio principale, che include tutti i sottodomini e le sottocartelle disponibili del tuo sito. Nelle impostazioni di Site Audit puoi specificare il tuo sottodominio o la tua sottocartella come ambito della scansione e deselezionare "Scansiona tutti i sottodomini" se non vuoi che altri sottodomini vengano analizzati.
Ad esempio, supponiamo che tu voglia analizzare solo il blog del tuo sito web. Puoi specificare l'ambito di crawling come blog.semrush.com o semrush.com/blog/ in base a come è stato implementato, come sottodominio o come sottocartella.
Limite di pagine per audit
Fatto questo, seleziona quante pagine vuoi scansionare per ogni audit. Scegli questo numero in maniera oculata, a seconda del livello del tuo abbonamento e della frequenza con cui intendi effettuare una nuova analisi del tuo sito web.
- Gli utenti del Toolkit SEO Pro possono eseguire la scansione di fino a 100.000 pagine al mese e 20.000 pagine per audit
- Gli utenti del Toolkit SEO Guru possono eseguire la scansione di 300.000 pagine al mese e 20.000 pagine per audit
- Gli utenti del Toolkit SEO Business possono eseguire la scansione di fino a 1 milione di pagine al mese e 100.000 pagine per audit
Pagine da analizzare
L'impostazione delle "Pagine da analizzare" determina il modo in cui il bot di Semrush Site Audit effettua la scansione del tuo sito web e trova le pagine da controllare. Oltre a impostare la fonte della scansione, puoi impostare le maschere e i parametri da includere o escludere dall'audit nei passaggi 3 e 4 della configurazione guidata.
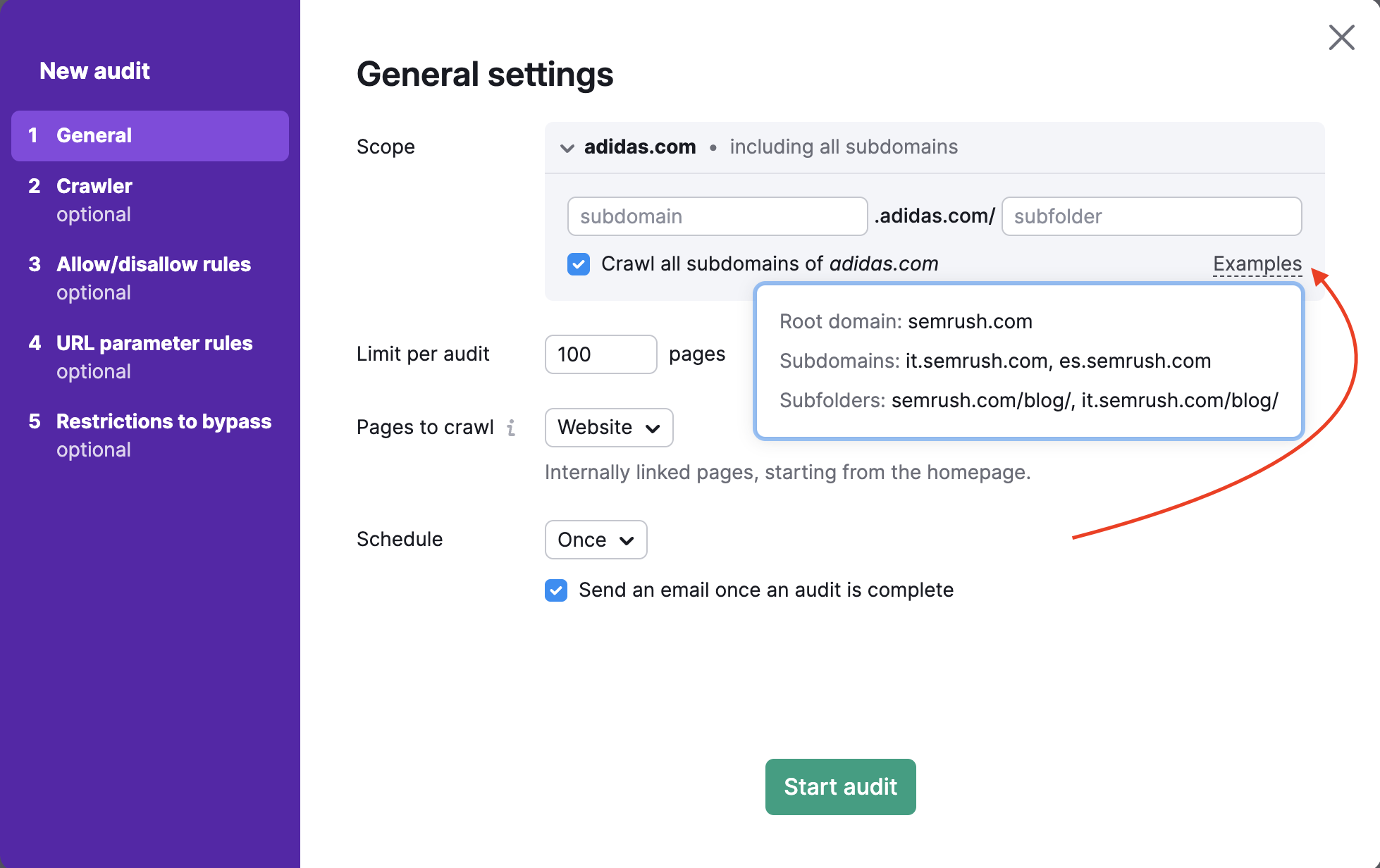
Ci sono 4 opzioni per impostare le tue "Pagine da scansionare": Sito web, Sitemap di Robots.txt, Sitemap da URL e file di URL.
1. Scansione da sito web significa che effettueremo la scansione del tuo sito come GoogleBot, utilizzando un algoritmo di ricerca breadth-first e navigando attraverso i link che vediamo nel codice della tua pagina, partendo dalla homepage.
Se vuoi eseguire la scansione solo delle pagine più importanti di un sito, scegliendo di effettuare la scansione da Sitemap invece che da Sito web l'audit scansionerà le pagine più importanti piuttosto che solo quelle più accessibili dalla homepage.
2. Scansione dalla sitemap di Robots.txt significa che effettueremo la scansione solo degli URL trovati nella sitemap collegata al file robots.txt.
3. Scansione da Sitemap da URL è simile alla scansione "Sitemap di Robots.txt", ma questa opzione permette di inserire specificamente l'URL della sitemap.
Dal momento che i motori di ricerca utilizzano le sitemap per capire quali pagine devono esaminare, dovresti sempre cercare di mantenere la tua sitemap il più aggiornata possibile e usarla come fonte con il nostro strumento per ottenere un audit accurato.
Nota: Site Audit può utilizzare solo un URL alla volta come fonte della scansione. Quindi se il tuo sito web ha diverse sitemap, l'opzione successiva (Importa URL da file) può funzionare come soluzione alternativa.
4. Crawl da un file di URL ti permette di controllare un insieme super-specifico di pagine di un sito web. Assicurati che il tuo file sia formattato correttamente come .csv o .txt con un URL per riga e caricalo direttamente su Semrush dal tuo computer.
Si tratta di un metodo utile se vuoi controllare pagine specifiche e risparmiare il tuo crawl budget. Se hai apportato delle modifiche solo a un piccolo gruppo di pagine del tuo sito che vuoi controllare, puoi utilizzare questo metodo per eseguire un audit specifico e non sprecare il budget per il crawling.
Dopo aver caricato il file la procedura guidata ti dirà quanti URL sono stati rilevati, in modo che tu possa ricontrollare che abbia funzionato correttamente prima di eseguire l'audit.
Pianifica
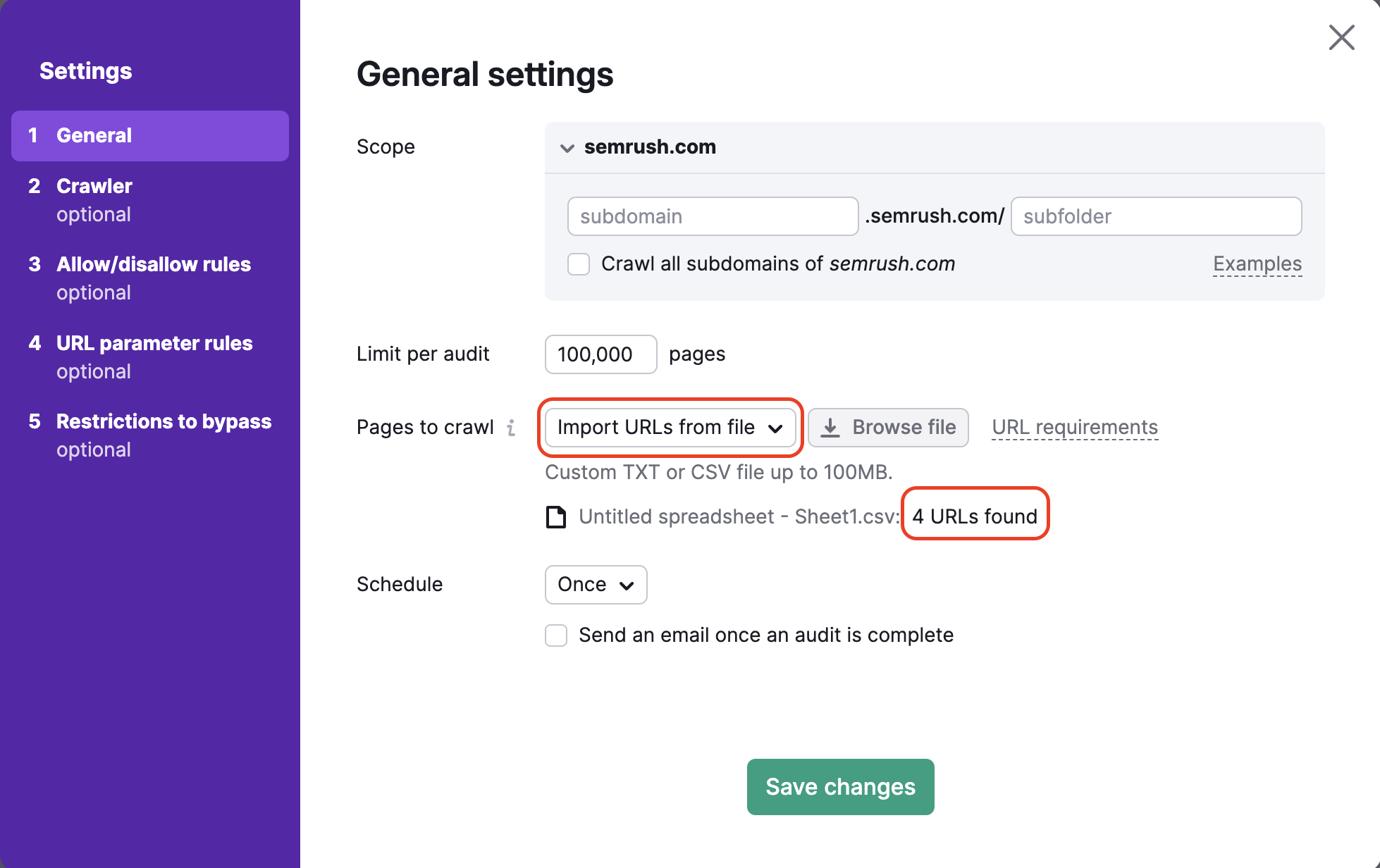
Infine, seleziona la frequenza con cui desideri che il tuo sito venga controllato automaticamente. Le opzioni sono:
- Settimanale (scegli un giorno qualsiasi della settimana)
- Giornaliero
- Una volta
Puoi sempre eseguire nuovamente l'audit quando preferisci.
Dopo aver completato tutte le impostazioni desiderate, seleziona "Avvia audit".
Impostazioni e configurazione avanzata
Nota: i passi successivi della configurazione sono opzionali e di livello avanzato.
Impostazioni crawler
Qui puoi scegliere l'user agent che desideri utilizzare per eseguire la scansione del tuo sito. Per prima cosa, imposta l'user agent della tua analisi scegliendo tra la versione mobile o desktop di SiteAuditBot o di GoogleBot. Puoi anche scegliere l'agente utente OpenAI-Search, che verificherà se il tuo sito web è scansionabile con il nuovo bot di ricerca.
Per impostazione predefinita controlliamo il tuo sito con il nostro crawler mobile che aiuta ad esaminare il tuo sito web nello stesso modo in cui il crawler mobile di Google navigherebbe il tuo sito web. Puoi passare al crawler desktop di Semrush in qualunque momento.
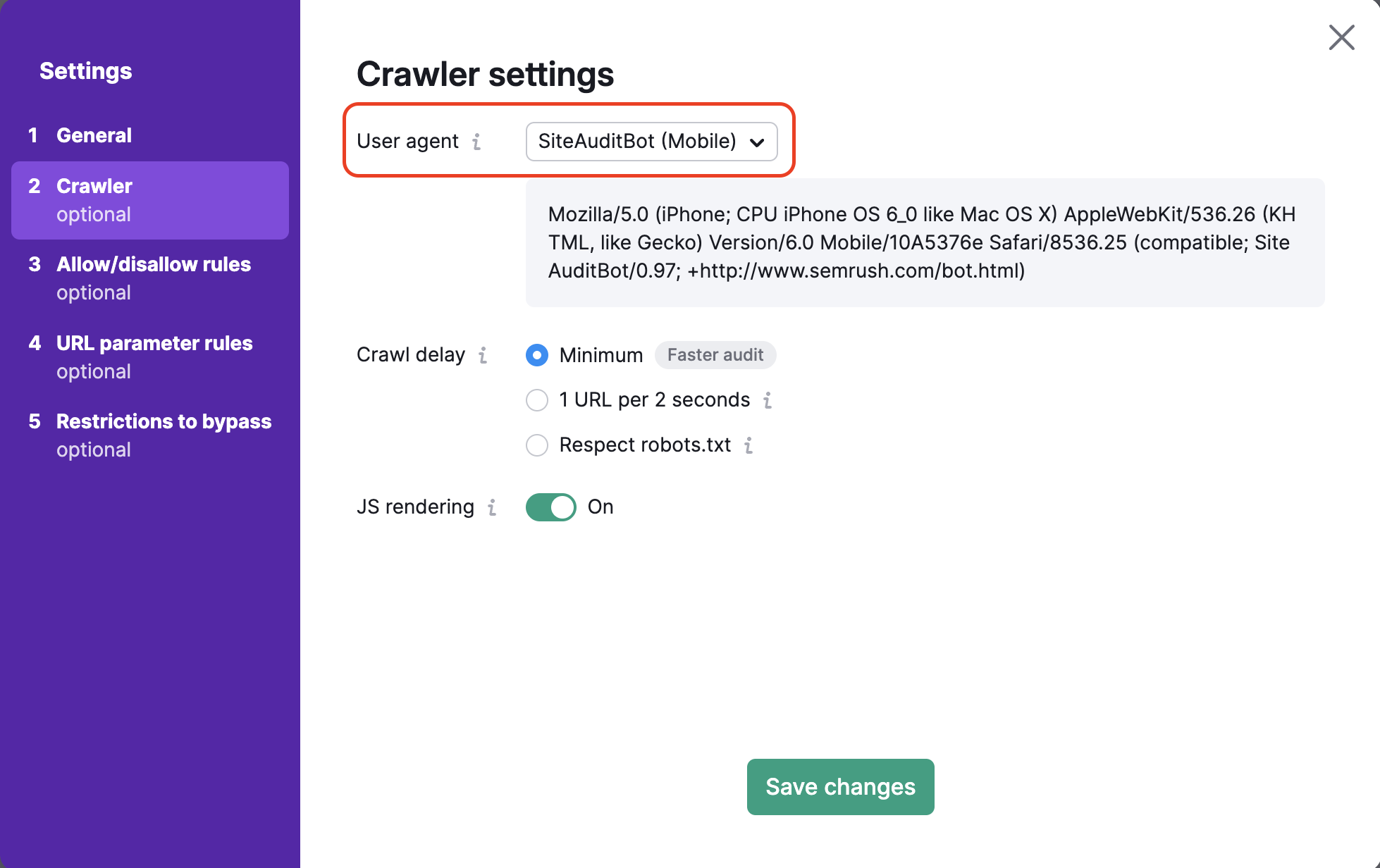
Quando cambi user agent vedrai anche la variazione del codice nella finestra di dialogo sottostante. Questo è il codice dell'user agent e può essere utilizzato in un URL di accesso client se vuoi testare l'user agent da solo.
Opzioni di crawl-delay
Hai 3 opzioni per impostare un ritardo di crawl: Ritardo minimo, Rispettare robots.txt e 1 URL ogni 2 secondi.
Se lasci selezionato il ritardo minimo tra le pagine, il bot effettuerà il crawling del tuo sito web alla sua normale velocità. Per impostazione predefinita, SiteAuditBot aspetterà circa un secondo prima di iniziare il crawling di un'altra pagina.
Se hai un file robots.txt sul tuo sito e hai specificato un ritardo di crawl, puoi selezionare l'opzione "rispettare robots.txt" per far sì che il nostro crawler di Site Audit segua il ritardo indicato.
Di seguito è riportato l'aspetto di un ritardo di crawl all'interno di un file robots.txt:
Crawl-delay: 20
Se il nostro crawler rallenta il tuo sito web e non hai una direttiva di ritardo di crawl nel tuo file robots.txt, puoi dire a Semrush di analizzare 1 URL ogni 2 secondi. In questo modo il completamento della verifica potrebbe richiedere più tempo, ma si ridurranno i potenziali problemi di velocità per gli utenti del tuo sito durante l'audit.
Analizzare i JavaScript
Se utilizzi JavaScript sul tuo sito, puoi attivare il rendering JS nelle impostazioni della tua campagna di Site Audit. Il rendering JavaScript permette al nostro crawler di eseguire i file JS e vedere gli stessi contenuti che vedono i visitatori del sito. In questo modo otterrai risultati di scansione più accurati (molto simili a quelli di Googlebot) e un quadro migliore della salute del tuo sito.
Se il rendering JS è disabilitato, Site Audit analizza solo l'HTML del sito. Sebbene la scansione dell'HTML sia più veloce e non rallenti il tuo sito web, i risultati dell'audit saranno meno accurati.

Tieni presente che questa funzione è disponibile solo per gli abbonamenti al toolkit SEO di livello Guru e Business.
Regole di allow/disallow
Per scansionare specifiche sottocartelle o bloccare determinate sottocartelle di un sito web, fai riferimento alla fase di impostazione di Site Audit "Abilita/disabilita URL". Questo step consente anche di eseguire l'audit di più sottocartelle specifiche contemporaneamente.
Includi tutto ciò che si trova all'interno dell'URL dopo il dominio di primo livello nella casella di testo sottostante. Ad esempio, se volessi eseguire la scansione della sottocartella http://www.esempio.it/scarpe/uomo/, dovresti inserire: "/scarpe/uomo/" nella casella di autorizzazione a sinistra.
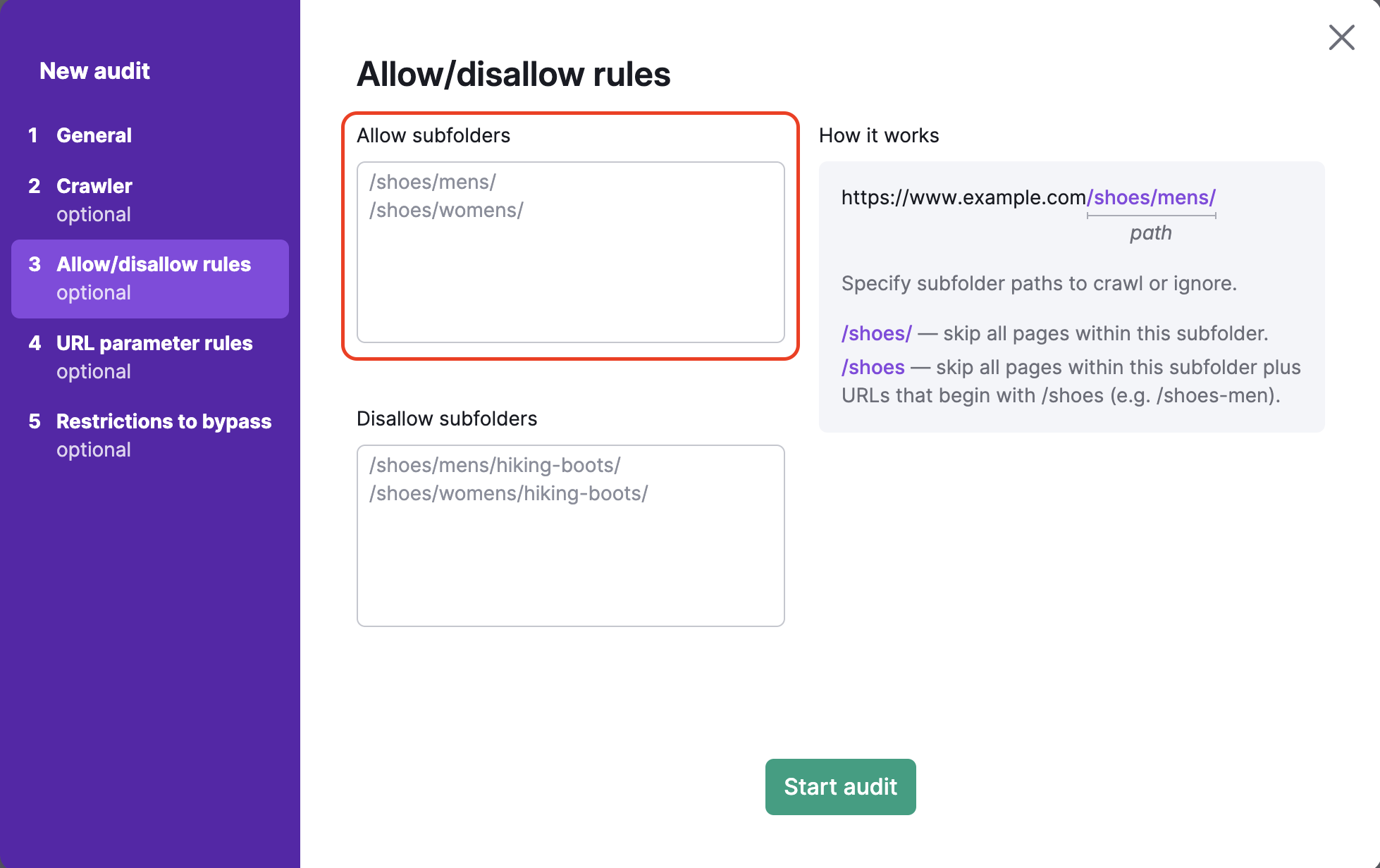
Per evitare il crawling di sottocartelle specifiche dovrai inserire il percorso della sottocartella nella casella di disabilitazione. Ad esempio, per scansionare la categoria delle scarpe da uomo ma evitare la sottocategoria degli scarponi da trekking sotto le scarpe da uomo (https://esempio.com/scarpe/uomo/scarponi-da-trekking/), devi inserire /scarpe/uomo/scarponi-da-trekking/ nella casella di disallow.
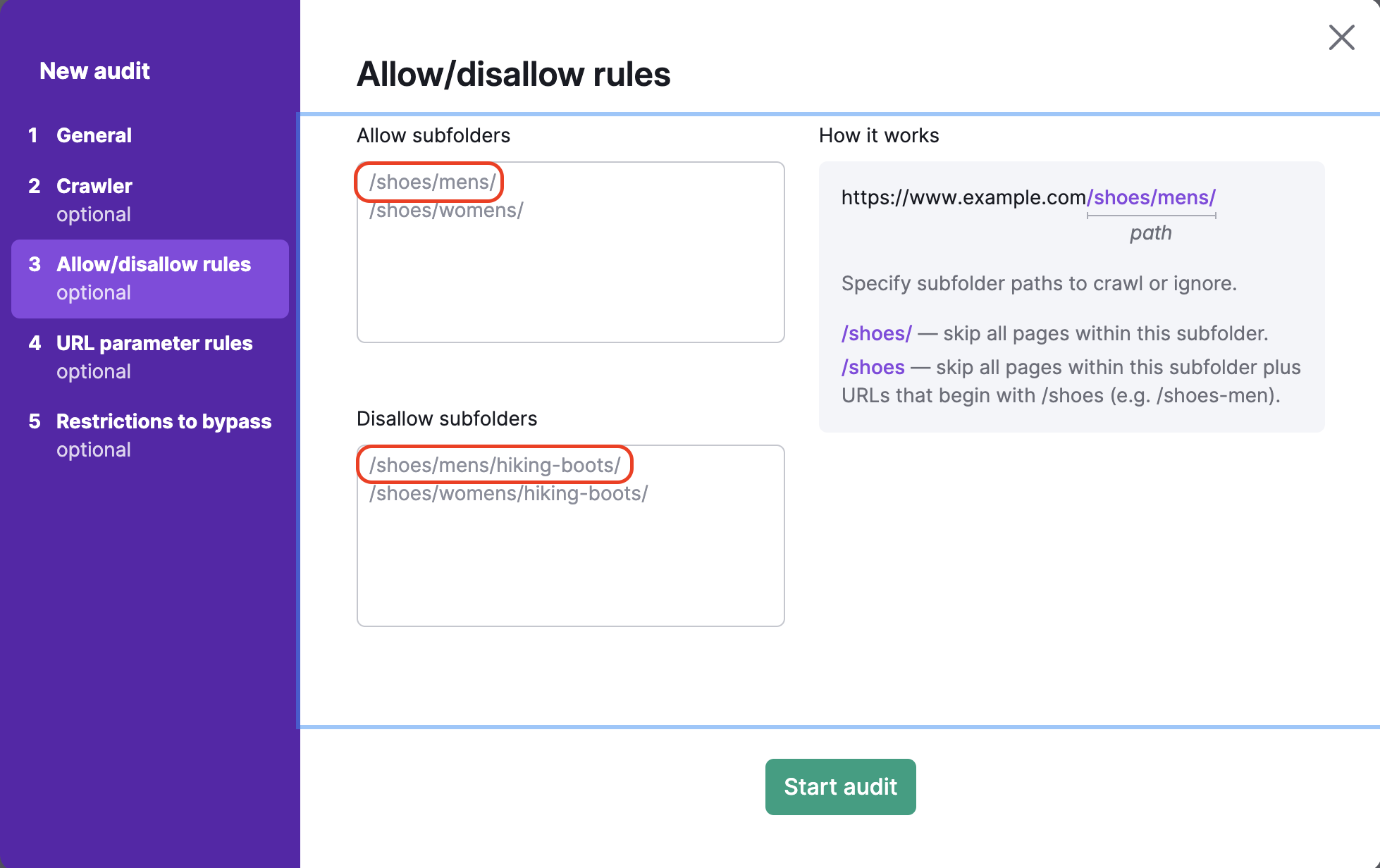
Se dimentichi di inserire la / alla fine dell'URL nella casella delle esclusioni (es: /scarpe), Semrush salterà tutte le pagine della sottocartella /scarpe/ e tutti gli URL che iniziano con /scarpe (come www.esempio.com/scarpe-uomo).
Regole dei parametri dell'URL
I parametri dell'URL (anche noti come stringhe di query) sono elementi di un URL che non si inseriscono nella struttura gerarchica del percorso. Invece, vengono aggiunti alla fine di un URL e forniscono istruzioni logiche al browser web.
I parametri URL sono sempre composti da un ? seguito dal nome del parametro (page, utm_medium, ecc.) e da =.
Quindi "?page=3" è un semplice parametro URL che può indicare la terza pagina di scorrimento su un singolo URL.
Il quarto step della configurazione di Site Audit ti permette di specificare eventuali parametri URL utilizzati dal tuo sito web per rimuoverli dagli URL durante il crawling. In questo modo Semrush eviterà di effettuare due volte il crawling della stessa pagina durante l'audit. Se un bot vede due URL, uno con un parametro e uno senza, potrebbe effettuare la scansione di entrambe le pagine, sprecando così il tuo Crawl budget sprecato.
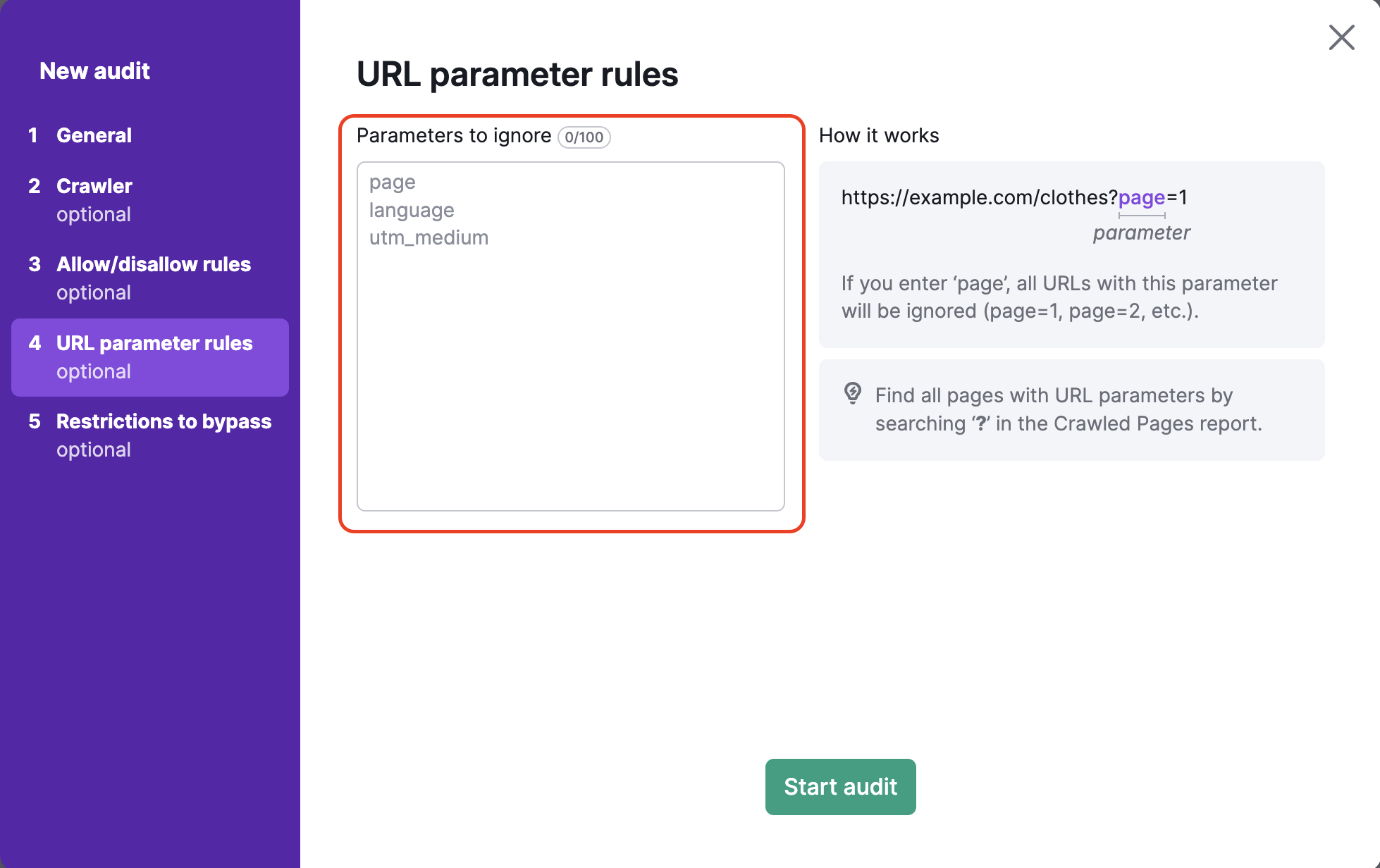
Ad esempio, se aggiungessi "page" in questa casella, verrebbero rimossi tutti gli URL che includono "page" nell'estensione dell'URL. Si tratta di URL con valori come ?page=1, ?page=2, ecc. Questo eviterebbe di eseguire la scansione della stessa pagina due volte (ad esempio, sia "/scarpe" che "/scarpe/?page=1" come un unico URL) nel processo di scansione.
Gli usi più comuni dei parametri URL includono pagine, lingue e sottocategorie. Questi tipi di parametri sono utili per i siti web con grandi cataloghi di prodotti o informazioni. Un altro tipo di parametro URL comune è l'UTM, che viene utilizzato per tracciare i clic e il traffico delle campagne di marketing.
Se hai già impostato una campagna di Site Audit e vuoi modificare le impostazioni, puoi farlo utilizzando l'ingranaggio Impostazioni:
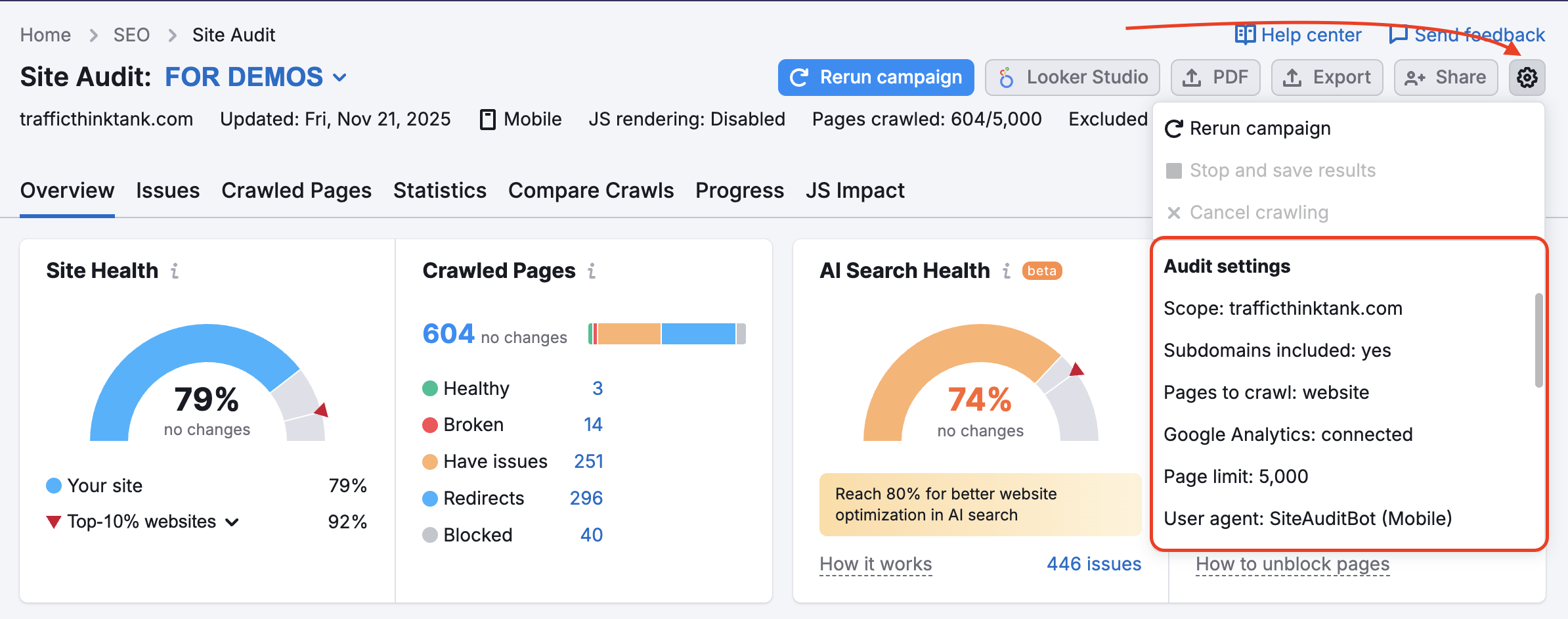
Utilizzerai le stesse indicazioni elencate sopra selezionando le opzioni "Maschere" e "Parametri rimossi".
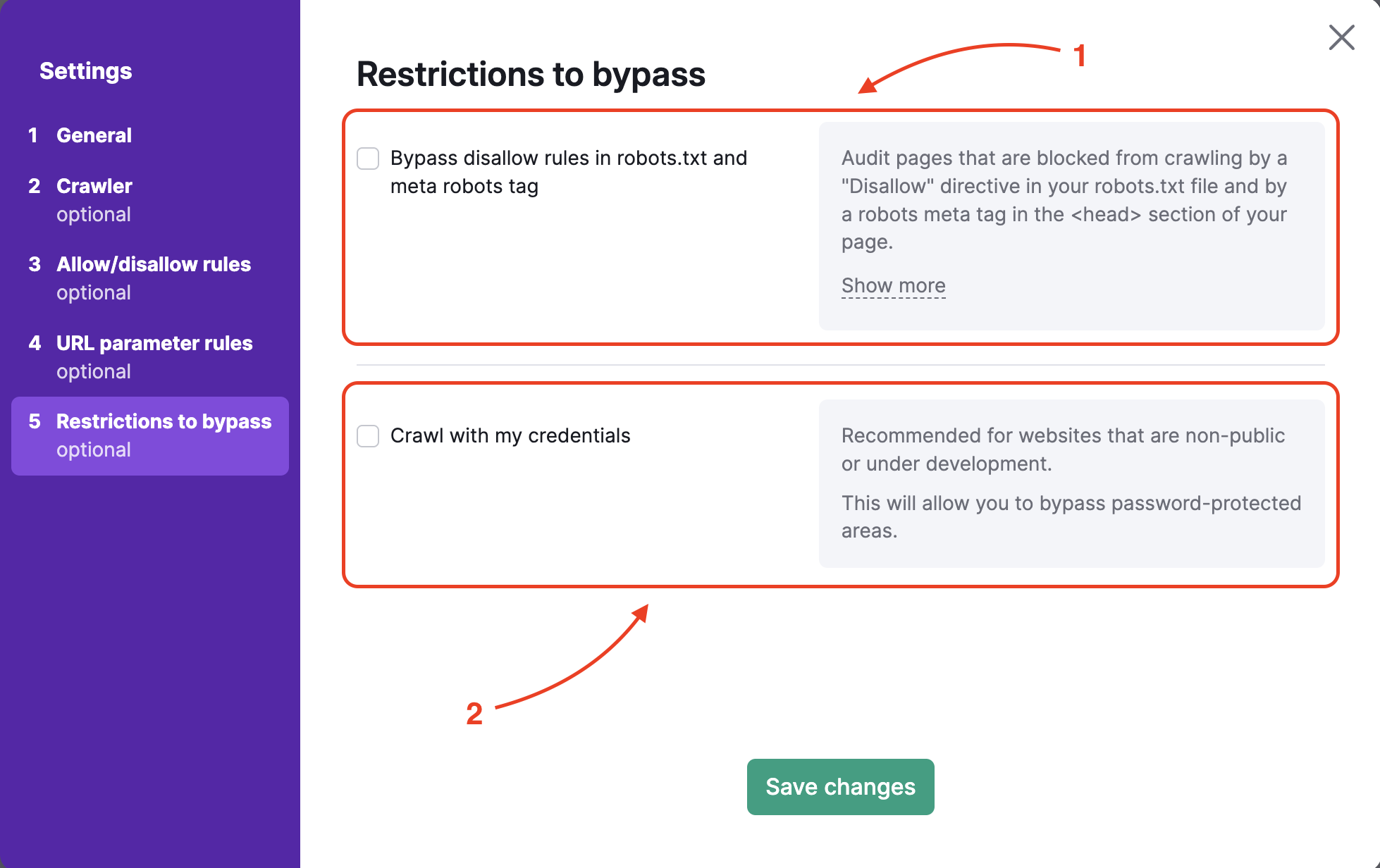
Restrizioni da aggirare
Per analizzare un sito web in pre-produzione o nascosto da una autenticazione di accesso di base, lo step 5 offre due opzioni:
- Ignorare la regola disallow all'interno di robots.txt e il tag meta robots
- Eseguire il crawling con le tue credenziali per aggirare le aree protette da password
Se vuoi bypassare i comandi di disattivazione nel file robots.txt o nel meta tag (di solito si trova nel tag del
tuo sito web), dovrai caricare il file .txt fornito da Semrush nella cartella principale del tuo sito web.Puoi caricare questo file nello stesso modo in cui caricheresti un file per la verifica GSC, ad esempio, direttamente nella cartella principale del tuo sito web. Questo processo verifica la proprietà del sito web e ci permette di effettuare il crawling del sito.
Una volta caricato il file, puoi avviare Site Audit e raccogliere i risultati.
Per effettuare il crawling con le tue credenziali, inserisci semplicemente il nome utente e la password che utilizzi per accedere alla parte nascosta del tuo sito web. Il nostro bot utilizzerà le tue informazioni di accesso per accedere alle aree nascoste e fornirti i risultati dell'audit.
Risoluzione dei problemi
Nel caso di una finestra di dialogo "l'audit del dominio non è andato a buon fine", dovrai verificare che il nostro crawler di Site Audit non sia bloccato dal tuo server. Per garantire un crawling corretto, segui i passaggi della sezione Risoluzione dei problemi di Site Audit per inserire il nostro bot nella whitelist.
In alternativa, puoi scaricare il file di log che viene generato quando la scansione non va a buon fine e fornirlo al tuo webmaster in modo che possa analizzare la situazione e cercare di trovare il motivo del blocco della scansione.
Collegare Google Analytics e Site Audit
Dopo aver completato l'installazione guidata, sarai in grado di collegare il tuo account Google Analytics per includere i problemi relativi alle tue pagine più visualizzate.
Se Site Audit continua ad avere problemi, consulta come risolvere i problemi di Site Audit.