Perché solo alcune delle pagine del mio sito sono state scansionate?
Se hai notato che solo 4-6 pagine del tuo sito web vengono scansionate (la home page, gli URL della sitemap e il file robots.txt), molto probabilmente è perché il nostro bot non è riuscito a trovare i link interni in uscita della tua homepage. Qui sotto troverai le possibili cause di questo problema.
È possibile che non ci siano link interni in uscita sulla tua pagina principale, oppure che siano incorporati nel JavaScript. Il nostro bot analizza i contenuti JavaScript solo nei livelli Guru e Business dell'abbonamento al Toolkit SEO. Pertanto, se non hai il livello Guru o Business e la tua homepage contiene link ad altre parti del tuo sito all'interno di elementi JavaScript, non rileveremo né effettueremo il crawling di queste pagine.
Sebbene la scansione deii JavaScript sia disponibile solo con i livelli Guru e Business, possiamo comunque effettuare la scansione dell'HTML delle pagine contenenti elementi JavaScript. Inoltre, i nostri controlli relativi alle prestazioni possono esaminare i parametri dei tuoi file JavaScript e CSS, indipendentemente dal livello di abbonamento.
In entrambi i casi, esiste un modo per garantire che il nostro bot esegua il crawling delle tue pagine. Per farlo, devi cambiare le "Pagine da scansionare" da "sito web" a "sitemap" o "URL da file" nelle impostazioni della campagna:
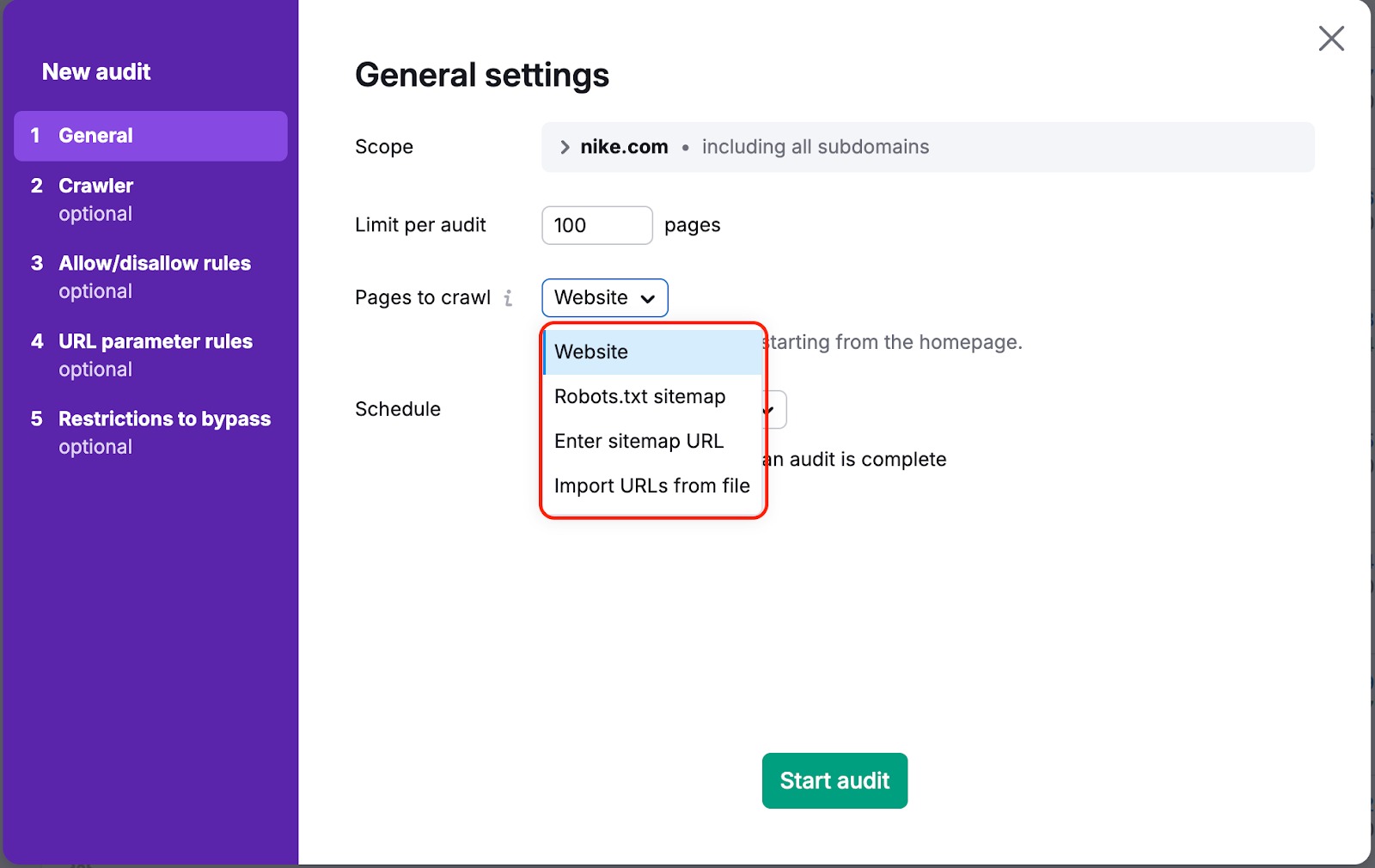
"Sito web" è la fonte predefinita. Significa che effettueremo il crawling del tuo sito web utilizzando un algoritmo di ricerca di tipo breadth-first e navigheremo attraverso i link che vediamo nel codice della tua pagina, a partire dalla homepage.
Se scegli una delle altre opzioni, effettueremo il crawling dei link presenti nella sitemap o nel file caricato.
Il nostro crawler potrebbe essere stato bloccato su alcune pagine nel file robots.txt del sito o da tag noindex/nofollow. Puoi verificare se questo è il caso nel tuo report Pagine sottoposte a crawling:
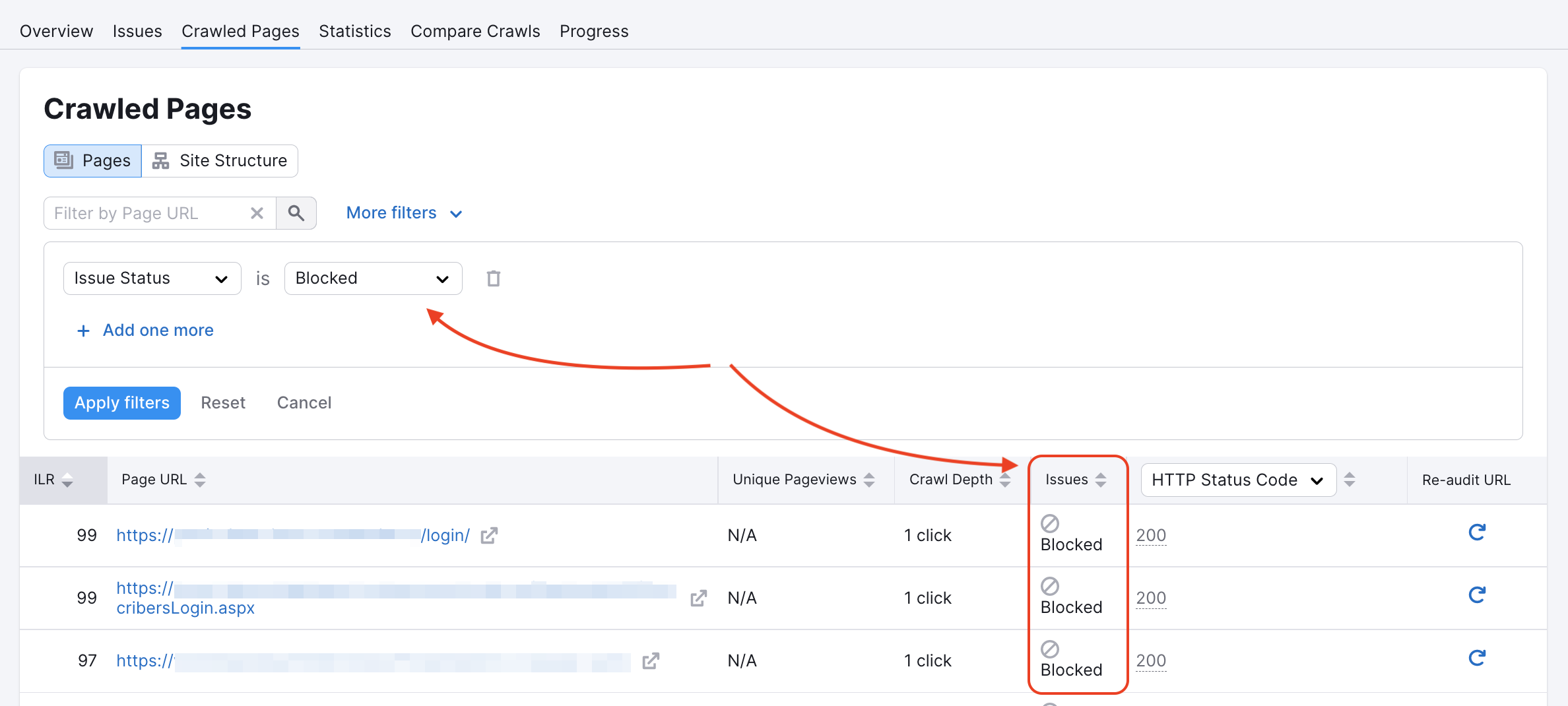
Puoi controllare il tuo Robots.txt alla ricerca di eventuali comandi Disallow che impediscano a crawler come il nostro di accedere al tuo sito web.
Se vedi il codice sottostante nella pagina principale di un sito web, ci dice che non siamo autorizzati a indicizzare i link presenti e che il nostro accesso è bloccato. Oppure, una pagina che contenga almeno uno dei due: "nofollow" o "none", porterà a un errore di crawling.
Troverai maggiori informazioni su questi errori nel nostro articolo sulla risoluzione dei problemi.
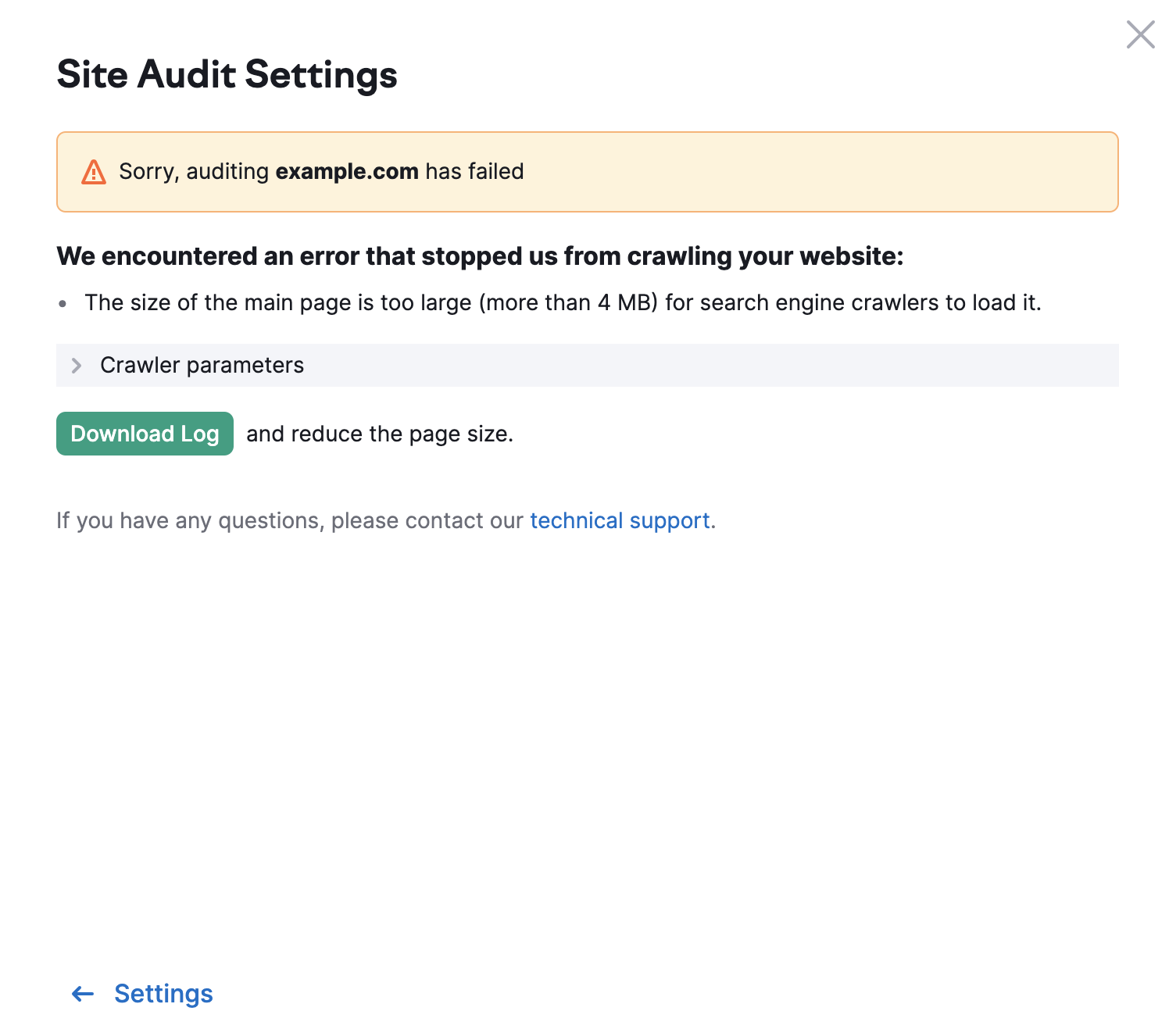
Il limite per le altre pagine del tuo sito web è di 2MB. Se le dimensioni dell'HTML di una pagina sono troppo grandi, vedrai il seguente errore:
